






Imagine duas pessoas tentando chegar ao mesmo destino. Uma tem um carro antigo com um mapa de papel; a outra, um veículo moderno com sistemas integrados, navegação em tempo real, otimização de rotas e assistência inteligente. As duas ainda estão dirigindo, e as duas continuam responsáveis por suas decisões. Mas uma delas vai se mover mais rápido, reagir mais rapidamente, processar mais informações e chegar ao destino de forma muito mais eficiente. Isso, em essência, é o que a Inteligência Artificial representa hoje. Como Sam Altman, CEO da OpenAI, disse: “A IA não vai substituir os humanos, mas os humanos que usam IA vão substituir os que não usam.”
Mas o carro excelente apenas melhora sua experiência de viagem; ele não te transforma em um bom motorista. Para realmente aproveitar a IA, o Anthropic AI Fluency Course define quatro etapas que importam. A primeira é a delegação: você deve saber para onde quer ir e entender o que a IA consegue fazer bem. A segunda é a descrição: você deve ser capaz de transmitir essa intenção à IA, dando a ela o papel a desempenhar, o contexto que deve usar e as regras que deve seguir. Se você não consegue configurar o sistema do carro e digitar o destino no GPS, o supercarro não vai te ajudar. Assim que você começa a dirigir, precisa de discernimento: a IA vai sugerir possibilidades, e você continua sendo o responsável por verificar se a rota que ela escolheu é realmente a certa para você. Quantas vezes o GPS escolheu uma rota rápida cheia de pedágios, ou uma que simplesmente não parece segura? Com a IA, é a mesma coisa. A última etapa é a diligência: nunca assine seu nome em algo que você não consiga explicar. Você pode delegar uma tarefa, mas nunca o entendimento por trás dela. Na nossa analogia, você pode ligar o piloto automático, mas não deve confiar nele tão completamente a ponto de não saber mais como retomar o volante quando algo der errado.
Em resumo, os quatro Ds formam uma cadeia. Delegação é sobre saber onde a IA ajuda e onde não ajuda. Descrição é sobre dar a ela o papel, o contexto e as regras de que precisa para fazer o trabalho. Esses dois vêm antes de o modelo ser usado. Os outros dois vêm depois: discernimento é verificar se a rota que a IA escolheu é a certa — se a abordagem faz sentido e se a saída é realmente útil e correta — e diligência é a consciência de que, por melhor que seja o assistente, a assinatura na resposta final é sua. Ao longo deste artigo, à medida que percorremos as formas como a IA agora se conecta aos modelos da PSR, essas quatro etapas valem a pena ser lembradas: elas são o que separa usar bem a IA de meramente usá-la.
O uso tradicional da IA
O primeiro passo para longe do mapa de papel foi a ascensão dos LLMs. A forma mais antiga de utilizá-los era a mais simples: escrever uma mensagem (um prompt), enviar ao modelo e ler a resposta que volta. Como isso funciona na prática? Os LLMs (Modelos de Linguagem de Grande Escala) são treinados em enormes conjuntos de dados textuais. As palavras são primeiro tokenizadas, ou seja, quebradas em pequenos pedaços e convertidas em IDs numéricos que o modelo pode processar. A partir desse treinamento, o modelo aprende a probabilidade de uma dada palavra ou frase seguir outra em um determinado contexto e usa essas probabilidades para gerar novos conteúdos sob demanda. É o que chamamos de IA generativa. Ela produz e-mails, resumos, trechos de código e rascunhos de relatórios. O resultado é genuinamente útil, mas tem limitações.
Um LLM genérico é restrito pelo conjunto de dados no qual foi treinado, e retreinar um modelo é caro o suficiente para que não possa ser feito em tempo real. A consequência é a falta de contexto. Se você perguntar ao IA sobre algo específico da PSR que não fazia parte do seu treinamento, ele não admite; ele adivinha, e o pior, faz isso com total confiança. Pergunte a ele, por exemplo, “o que é uma estação renovável no SDDP?” e o modelo responderá usando informações públicas sobre o conceito físico de usinas renováveis, algo como: “Uma Estação Renovável é uma instalação de geração de energia que produz eletricidade a partir de fontes de energia naturalmente renováveis, como solar, eólica, hídrica ou biomassa.” É o que chamamos de alucinação.
Inteligência fundamentada: um assistente que conhece a PSR
Para suprir essa falta de contexto, o LLM deve de alguma forma acessar o próprio conhecimento da PSR. Como retreinar completamente o modelo com a documentação da PSR seria caro, imagine que podemos conectar um pen-drive ao LLM no momento em que ele precisa ser respondido. A técnica que faz exatamente isso é a Geração Aumentada por Recuperação (RAG). Ela funciona em quatro pequenas etapas. Primeiro, a documentação da PSR (manuais, notas metodológicas, exemplos) é dividida em pedaços menores chamados chunks, tokenizada e incorporada em um índice vetorial, para que fale a mesma linguagem numérica que o LLM usa para gerar texto (0). Quando um usuário faz uma pergunta (1), a própria pergunta também é vetorizada, e uma busca por similaridade usando distância de cosseno retorna as passagens cujo significado está mais próximo. Essas passagens são injetadas no prompt como contexto, para que o LLM receba tanto a pergunta do usuário quanto a documentação de que precisa para respondê-la corretamente — exatamente a etapa de descrição de que falamos no parágrafo de abertura (2). O LLM então compõe uma resposta fundamentada a partir dessa evidência, e não a partir do seu treinamento geral (3).
O PSR Assistant usa exatamente essa técnica para permitir que os usuários façam perguntas específicas sobre a PSR. Ele não apenas responde à pergunta; também retorna o link para a página relevante no PSR Knowledge Hub, para que o usuário possa verificar a informação. Além de evitar alucinações, o ganho real é tempo: em vez de pesquisar em centenas de páginas, o usuário obtém uma resposta direta com fonte. O Assistant tem dois “irmãos” construídos sobre o mesmo padrão, mas fundamentados no código-fonte das bibliotecas da PSR — um para o PSR Factory, nossa API de automação em Python, e outro para o PSRIO, nossa ferramenta de BI. Para usuários que ainda não dominam essas bibliotecas, eles resolvem o problema da página em branco: basta pedir um script típico e receber um ponto de partida funcional que pode ser adaptado.
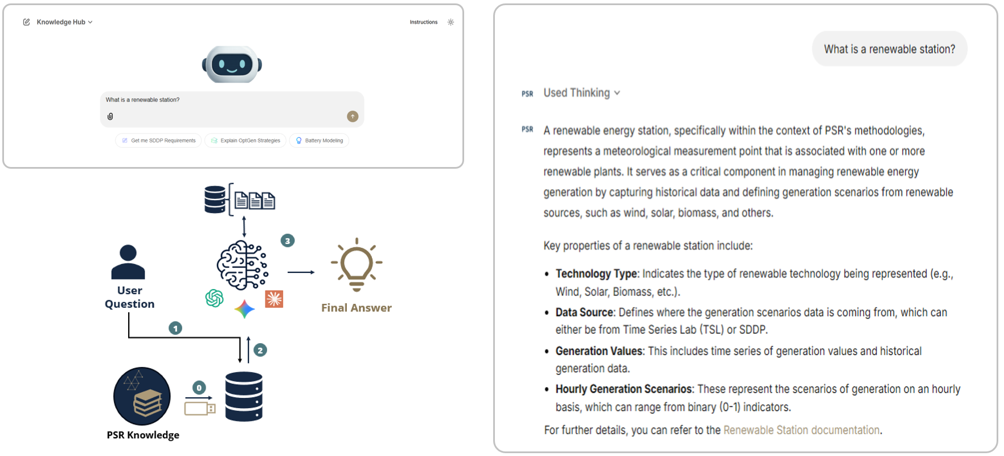
Figure 1 — RAG anchors the LLM on PSR’s own documentation, replacing hallucinated definitions with grounded, sourced answers.
IA agêntica: de respostas a ações
Mas e se a IA pudesse ir além de gerar conteúdo e começar a executar tarefas? Imagine que o trabalho manual que um analista realiza todos os dias — descobrir os dados de entrada de um modelo, editar esses dados, executar casos localmente ou na nuvem, visualizar os resultados — pudesse ser transformado em tarefas automatizadas acionadas por uma única solicitação em linguagem natural. Esta é a terceira etapa da jornada: da IA generativa à IA agêntica, um sistema projetado para executar fluxos de trabalho complexos combinando planejamento autônomo, memória de longo prazo e a capacidade de interagir com aplicações externas. Mas se o LLM ainda tem dados limitados, como ele pode saber sobre nossos dados?
Plataformas modernas de IA — da OpenAI, da Anthropic e de outras — agora suportam ramificações personalizadas que dão ao modelo acesso a aplicações externas. O modelo então se comporta como um orquestrador: ele usa essas ramificações, juntamente com seu próprio LLM, para executar tarefas para o usuário. Para executar uma tarefa automaticamente, o modelo precisa de acesso a uma função de código personalizada que possa chamar e que, por sua vez, possa acessar fontes de dados externas. A forma padrão de fazer essa conexão é o Model Context Protocol (MCP), um protocolo aberto que permite que qualquer LLM interaja com sistemas externos por meio de uma interface consistente. Um servidor MCP publica um catálogo de ferramentas — funções tipadas, cada uma com uma descrição clara — que o modelo pode navegar e invocar. O PSR Agent é o nosso servidor MCP. Ele expõe funções que, por meio da API Python do PSR Factory, conversam com os bancos de dados dos modelos PSR. A orquestração geralmente começa com um plano interno do que deve ser feito; o modelo então compara esse plano com as descrições no catálogo de ferramentas, por similaridade, e seleciona a ferramenta que melhor corresponde à tarefa em questão.
Para que a IA faça tudo isso bem, ela precisa de uma boa descrição de como essas ferramentas funcionam e qual fluxo de trabalho deve ser usado para cada tarefa. Mas seria tedioso escrever essas instruções do zero toda vez. A solução natural é empacotá-las uma vez e reutilizá-las. Esta é a ideia por trás das Habilidades (Skills): pacotes de instruções, exemplos e scripts auxiliares que o agente carrega sob demanda quando reconhece um tipo de tarefa familiar. Onde o MCP dá à IA acesso, as Habilidades lhe dão expertise — a ordem correta em que chamar as ferramentas, as armadilhas comuns a evitar, o estilo da PSR para relatar resultados. Um fluxo de trabalho típico está ilustrado abaixo; ao final dele, o LLM é utilizado mais uma vez, desta vez para redigir o resultado ou para relatar uma mensagem de sucesso ou falha.
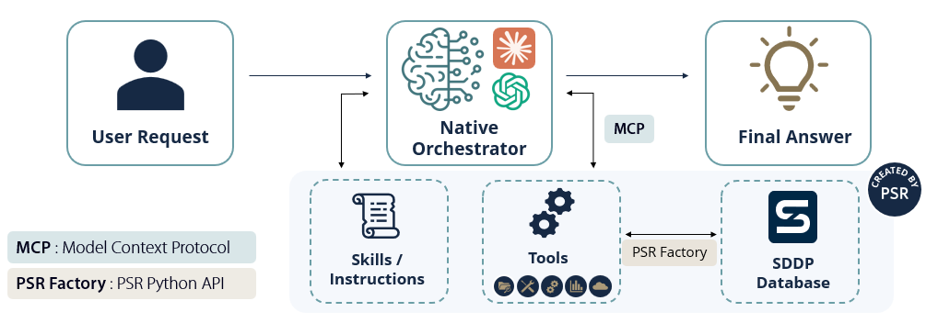
Figure 2 — The PSR Agent: an AI model uses its LLM to discover and load Skills for domain expertise, accesses PSR tools through MCP, and reads from and writes to the SDDP database via PSR Factory.
A caixa de ferramentas que a PSR incorporou ao Agent está centrada nas partes do dia que levam mais tempo. Localizar um objeto, navegar por suas relações ou filtrar elementos por condição se torna uma única pergunta, em vez de uma sequência de abas e cliques pela interface. Operações em massa repetitivas — atualizar capacidades, escalar séries temporais, criar novos objetos — podem ser executadas automaticamente em um modo de cópia segura que preserva o caso original. Simulações no SDDP, no OptGen e no NCP podem ser iniciadas diretamente da conversa, com o Agent monitorando o status de execução e extraindo resumos estruturados de erros, avisos e informações de convergência dos logs de execução. Comparações de cenários, cálculos de receita e análises de resultados também podem ser realizados por meio da conversa; uma única instrução é suficiente para empacotar as saídas e notificar a equipe.
Em resumo, o conjunto atual de ferramentas foi projetado para reduzir o trabalho operacional repetitivo realizado tradicionalmente pela interface gráfica. O projeto deve evoluir de forma incremental: à medida que novos fluxos de trabalho recorrentes e necessidades dos usuários forem identificados, capacidades adicionais serão incorporadas ao Agent ao longo do tempo.
Na prática, um único prompt como “atualize a capacidade instalada da Usina X para 1.350 MW, execute o SDDP para o horizonte de 2026 e envie os resultados por e-mail para a equipe de operações” já corresponde a um fluxo de trabalho que anteriormente exigia várias etapas manuais em diferentes interfaces. O usuário ainda revisa as ações propostas e valida a resposta final, mas o atrito operacional cai drasticamente.
A próxima etapa: uma camada de raciocínio
Fundamentar o LLM no conhecimento da PSR e conectá-lo às ferramentas da PSR cobre as partes de “informação” e “execução” do problema. A terceira peça, ainda em desenvolvimento, é a camada de análise: um agente que não apenas responde perguntas ou executa tarefas operacionais sob demanda, mas interpreta resultados de simulações, formula hipóteses sobre o que os está impulsionando e obtém os dados necessários para testar essas hipóteses.
O protótipo, atualmente em desenvolvimento, está estruturado como um pipeline multiagente. Um orquestrador despacha a solicitação do usuário para subagentes especializados — um para classificação do problema, um para hipótese de causa, um para descoberta de dados — cada um com seu próprio conjunto restrito de ferramentas. O orquestrador então combina suas saídas em uma única resposta sintetizada, com evidências rastreáveis que o analista pode auditar passo a passo.
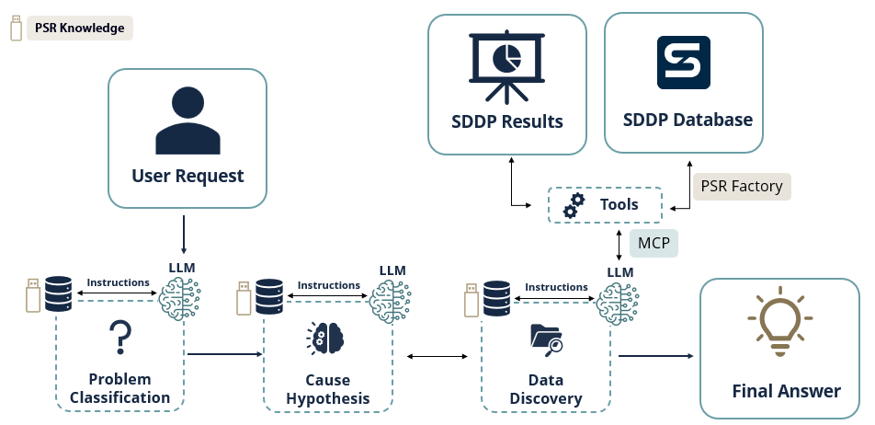
Figure 3 — Reasoning agent under development: specialized sub-agents classify the problem, generate hypotheses and discover data, then return a synthesized, evidence-backed analytical answer.
Juntos, RAG, IA agêntica e a camada de raciocínio traçam um caminho claro para a IA dentro da PSR: de explicar os modelos, para operá-los, para raciocinar sobre seus resultados. O objetivo não é substituir o analista, mas retirar o trabalho rotineiro do prato do analista, para que o tempo economizado seja dedicado ao que realmente requer julgamento humano.
