






Introdução
A energia hidrelétrica é a maior fonte de eletricidade de baixo carbono do mundo, fornecendo cerca de um sétimo da geração global. Além de sua escala, é também um dos recursos mais flexíveis nos sistemas elétricos modernos: grandes reservatórios podem armazenar água por meses e liberá-la sob demanda, suavizando a variabilidade sazonal e absorvendo choques em outras partes do sistema. Essa mesma capacidade de armazenamento, porém, é o que torna o despacho hidrotérmico um problema de planejamento tão difícil. Uma decisão de turbinar ou reter água hoje pode não revelar seu verdadeiro custo ou valor por muitos meses, e essa longa memória precisa ser conciliada com as realidades operacionais do dia a dia, como limites de transmissão, disponibilidade das usinas termelétricas e a crescente variabilidade das renováveis.
Por mais de três décadas, uma ferramenta central para esse problema tem sido a Programação Dinâmica Dual Estocástica (PDDE — ou SDDP, em inglês), um algoritmo utilizado em estudos de planejamento da operação em países como Brasil, Bolívia, Noruega, Vietnã e Estados Unidos. Em sua forma clássica, o SDDP depende de duas hipóteses estruturais: a incerteza deve ser representada de forma que preserve a independência por estágio após uma transformação adequada, e o problema de otimização subjacente deve ser convexo. Essas hipóteses são parte do que torna o método tratável em escala, mas também moldam as escolhas de modelagem disponíveis na prática — por exemplo, na forma como os processos de afluências são representados.
Este artigo resume um estudo recente que explora um caminho alternativo: combinar a otimização com o Aprendizado por Reforço (AR) de forma que mantenha o rigor da satisfação de restrições, ao mesmo tempo em que relaxa a hipótese de independência por estágio que o SDDP impõe ao modelo de afluências. O objetivo não é substituir o SDDP, que continua sendo uma referência sólida, mas entender o que se torna possível quando essa restrição estrutural é relaxada, e a que custo.
Aprendizado por Reforço Profundo no contexto de sistemas de potência
O Aprendizado por Reforço Profundo (ARP) passou por uma maturação excepcionalmente rápida na última década. A área se destacou com agentes que aprenderam a jogar jogos de Atari a partir de pixels brutos, avançou ainda mais com AlphaGo e AlphaZero, que dominaram o Go, o xadrez e o shogi inteiramente por autoaprendizado. Mais recentemente, a mesma família de técnicas se tornou um ingrediente rotineiro no treinamento de modelos de linguagem de grande escala por meio de aprendizado por reforço com feedback humano. Cada um desses marcos impulsionou os algoritmos para a frente: métodos actor-critic eficientes em amostras, como o Deep Deterministic Policy Gradient (DDPG), o Twin Delayed DDPG (TD3) e o Soft Actor-Critic (SAC), além de variantes baseadas em modelos que planejam sobre um modelo interno do ambiente. O resultado é um conjunto de ferramentas muito mais prático, muito mais estável e muito menos dependente de dados do que o que estava disponível mesmo cinco anos atrás.
Por baixo das variações algorítmicas, todos os métodos de AR compartilham uma estrutura comum: um ciclo entre um agente e um ambiente. A cada passo de tempo, o agente observa o estado do ambiente e escolhe uma ação; o ambiente transita para um novo estado e retorna uma recompensa que avalia a escolha. Repetir esse ciclo ao longo de todo o horizonte define um episódio. O objetivo do agente é aprender uma política (uma regra que mapeia estados observados para ações) que maximize a recompensa acumulada ao longo de um episódio.
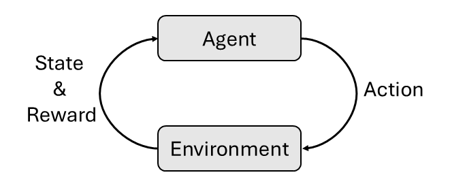
Figure 1 – O framework de aprendizado por reforço
Do ponto de vista dos sistemas de potência, o que torna o ARP interessante é seu parentesco subjacente com os algoritmos que os operadores já utilizam. O ARP baseado em valor e o SDDP são surpreendentemente primos próximos: ambos alternam entre um passo de simulação progressiva e uma atualização retroativa que aprimora uma estimativa da função de custo futuro de longo prazo. O SDDP representa essa função com cortes convexos lineares por partes, o que lhe confere sua notável eficiência em problemas convexos. O ARP substitui esses cortes por redes neurais, que são aproximadores universais de funções. Curiosamente, quando a rede utiliza ativações ReLU, como a maioria das arquiteturas modernas, a aproximação resultante da função de custo futuro também é linear por partes, mas não é mais obrigada a ser convexa. Em outras palavras, o ARP pode ser lido como uma generalização da mesma ideia por trás do SDDP.
Essa generalização está começando a se traduzir em aplicações concretas em sistemas de potência. O ARP foi utilizado para o despacho de energia em tempo real em microrredes isoladas baseadas em IoT (Lei et al., 2021), e pesquisas recentes documentam uma gama crescente de casos de uso adicionais, incluindo gerenciamento de tensão e potência reativa em alimentadores de distribuição, estratégias de lances em mercados de eletricidade e a operação de armazenamento em baterias em sistemas com alta penetração de renováveis (Sivamayil et al., 2023).
O problema de despacho hidrotérmico é outro caso de uso, marcado por um horizonte multipluranual impulsionado pelo acoplamento temporal dos reservatórios e por restrições físicas rígidas na rede e nos balanços hídricos. A aproximação da função de custo futuro do ARP pode representar o valor não linear e temporalmente acoplado da água armazenada ao longo desse horizonte, mas as restrições são um ponto fraco das abordagens de AR puras. Combinar o ARP com uma camada de otimização que satisfaça essas restrições a cada estágio é o que torna essa abordagem híbrida viável na prática.
A abordagem proposta: rastreamento de alvo com uma política aprendida
O método tem dois componentes que funcionam em conjunto. A cada estágio mensal, um problema de otimização decide quais usinas termelétricas e hidrelétricas despachar, satisfazendo o balanço de carga, o balanço hídrico, os limites de geração e o conjunto completo de restrições de rede. O que muda é como o valor de longo prazo da água armazenada é comunicado ao problema de estágio único. Em vez da função de custo futuro linear por partes utilizada pelo SDDP, um agente de AR (implementado aqui como um actor-critic DDPG) gera um volume alvo de reservatório para cada usina hidrelétrica, juntamente com um peso de penalidade que controla com que força a operação deve ser direcionada para esse alvo.
O problema de estágio único minimiza então o custo operacional imediato mais uma penalidade sobre o desvio entre os volumes finais do reservatório e os alvos fornecidos pelo agente. Se o agente recomenda manter os reservatórios cheios, a água é armazenada de forma agressiva; se o agente prefere reduzir o nível, o otimizador libera água na medida em que as restrições permitem. O custo operacional simulado é retornado como sinal de recompensa, e as redes actor e critic são treinadas gradualmente para recomendar alvos que minimizem o custo total ao longo de todo o horizonte de planejamento.
Duas escolhas de projeto merecem destaque. Primeiro, a camada de otimização é o que garante a viabilidade: o agente de AR nunca precisa aprender o que é uma restrição de rede, porque o otimizador a satisfaz para cada decisão de despacho. Segundo, dividir o problema dessa forma (otimização de estágio único para a decisão imediata, AR para o acoplamento de longo prazo) remove as restrições estruturais que os solvers multiestágio normalmente impõem à modelagem. Em particular, o processo de afluências pode ser qualquer modelo que conduza a simulação: dados históricos, um modelo de séries temporais flexível ou qualquer outro processo que acreditemos representar melhor a realidade.
A Figura 2 mapeia essas peças em um único estágio. A entrada do agente é o estado atual st (níveis dos reservatórios e defasagens de afluências recentes), juntamente com as incertezas realizadas no estágio ωt (afluências e demanda). Sua ação tem duas partes: um vetor de volumes alvo de reservatório ŝt+1 e um peso de penalidade βt que controla com que força o otimizador deve rastrear esses alvos. A resolução do problema de rastreamento de estado com essas entradas fornece o próximo estado realizado st+1 e o custo operacional imediato ct, que é retornado como sinal de recompensa utilizado para treinar o agente.
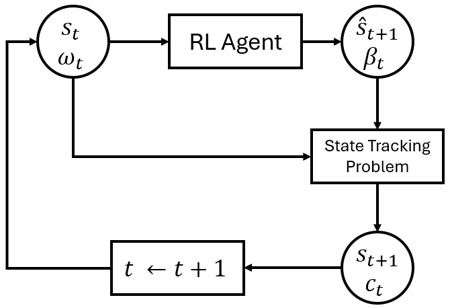
Figura 2 — Fluxo de informações entre o agente de AR e o problema de otimização de rastreamento de estado de estágio único
Estudo de caso: modelo de afluências
A abordagem proposta é comparada ao SDDP em um contexto em que as hipóteses estruturais do SDDP forçam uma simplificação de modelagem que o método híbrido pode evitar: o modelo de afluências com independência por estágio exigido pelo SDDP. O sistema de teste é o sistema elétrico boliviano (28 barras, 11 usinas hidrelétricas, 23 usinas termelétricas e 31 ramais de transmissão), simulado ao longo de um horizonte de 5 anos dividido em 60 estágios mensais. As políticas são comparadas nos mesmos 10.000 cenários de afluências fora da amostra extraídos de um modelo SARIMA ajustado ao histórico de afluências, e cada configuração de AR é treinada cinco vezes com diferentes sementes aleatórias para considerar a variabilidade decorrente da inicialização da rede neural.
O SDDP foi treinado com cenários de um modelo PAR(p), conforme exigido por sua hipótese de independência por estágio. Três variantes de AR foram treinadas com diferentes entradas de afluências: o próprio registro histórico artificial, um gerador baseado em SARIMA correspondente ao processo gerador de dados fora da amostra e o mesmo modelo PAR(p) utilizado pelo SDDP.
Os resultados mostram uma ordenação clara entre as variantes de AR. O treinamento com cenários extraídos do processo gerador de dados real, mesmo em número limitado, produziu custos operacionais menores do que o treinamento com cenários PAR(p), com uma redução de cerca de 5%. A geração de um número ilimitado de cenários SARIMA reduziu ainda mais os custos, confirmando que modelos de afluências flexíveis combinados com dados de treinamento abundantes levam a melhores políticas. O SDDP, no entanto, ficou à frente de todas as variantes de AR, com a melhor configuração de AR ficando a cerca de 5% do custo do SDDP.
Duas observações práticas emergiram. Primeira, a hipótese de modelagem de afluências comumente utilizada no planejamento operacional não é inócua: substituir o PAR(p) por um processo estocástico mais rico alterou os custos totais de operação em vários pontos percentuais, mantendo todas as demais hipóteses fixas. Segunda, a variabilidade entre sementes teve um impacto significativo: diferentes inicializações levaram a diferentes níveis de reservatório no final do horizonte, reforçando a importância de avaliar múltiplas sementes em qualquer implantação prática.
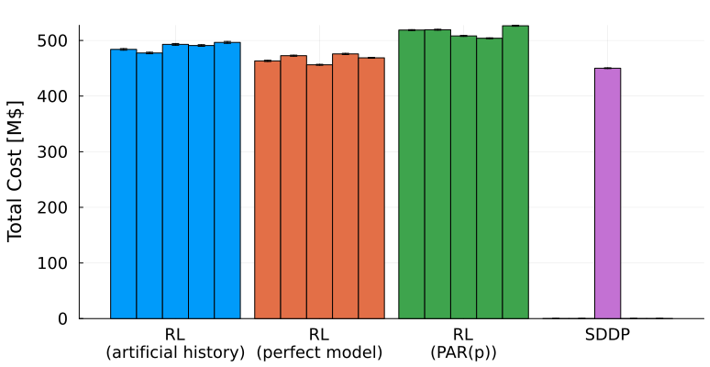
Figura 3 — Custo operacional total para diferentes sementes aleatórias
Discussão e perspectivas
Os experimentos sustentam uma conclusão ponderada. Combinar otimização e Aprendizado por Reforço é uma forma prática de construir políticas de despacho hidrotérmico sem impor a hipótese de independência por estágio que o SDDP exige em seu modelo de afluências. O otimizador de estágio único mantém cada restrição física viável, enquanto a política aprendida fornece o acoplamento temporal que o SDDP de outra forma imporia por meio de sua função de custo futuro linear por partes. Dentro desse framework, treinar a política com cenários mais próximos do processo gerador de dados real reduziu os custos de forma consistente entre as sementes, sugerindo que a restrição PAR(p) rotineiramente embutida no planejamento operacional carrega peso econômico real. A contrapartida honesta é que o SDDP permaneceu a abordagem mais custo-efetiva nas condições testadas. O método híbrido reduziu a lacuna quando o modelo de afluências foi relaxado, mas não a eliminou.
Várias direções de pesquisa parecem promissoras para explorar as vantagens potenciais do ARP. Paralelizar a otimização interna entre os cenários melhoraria a eficiência do treinamento, especialmente quando a solução por estágio é cara — por exemplo, quando restrições de rede ou operacionais mais ricas são introduzidas. Algoritmos de AR mais recentes, como o Twin Delayed DDPG e o Soft Actor-Critic, abordam alguns dos problemas de estabilidade do DDPG e poderiam melhorar a eficiência amostral. E como já temos um modelo explícito dentro da camada de otimização, o AR baseado em modelos (a família de algoritmos por trás de sistemas como o AlphaZero) é uma escolha natural: o agente poderia avaliar vários volumes alvo candidatos resolvendo o problema de estágio único para cada um e usar essa informação para planejar com mais eficácia.
O ARP em si é um conjunto de ferramentas em desenvolvimento, e não um produto acabado. A área avançou substancialmente nos últimos anos, com algoritmos de treinamento mais estáveis, melhor eficiência amostral e pesquisas ativas sobre como escalar para os tipos de grandes espaços de estado e ação característicos dos sistemas de potência. Para problemas de planejamento de longo horizonte, como o despacho hidrotérmico, acreditamos que o caminho mais provável é híbrido: a otimização lida com o que faz melhor, ou seja, satisfazer restrições físicas e produzir decisões tratáveis por estágio, enquanto o ARP lida com o acoplamento temporal e as partes do problema que resistem à modelagem convexa.
References
Pereira, M.V.F. and Pinto, L.M.V.G. (1991). Multi-stage stochastic optimization applied to energy planning. Mathematical Programming, 52(1), 359–375.
Rosemberg, A.W., Street, A., Garcia, J.D., Valladão, D.M., Silva, T. and Dowson, O. (2022). Assessing the cost of network simplifications in long-term hydrothermal dispatch planning models. IEEE Transactions on Sustainable Energy, 13(1), 196–206.
Lillicrap, T.P. et al. (2015). Continuous control with deep reinforcement learning. arXiv:1509.02971.
Lei, L., Tan, Y., Dahlenburg, G., Xiang, W. and Zheng, K. (2021). Dynamic energy dispatch based on deep reinforcement learning in IoT-driven smart isolated microgrids. IEEE Internet of Things Journal, 8(10), 7938–7953.
Sivamayil, K., Rajasekar, E., Aljafari, B., Nikolovski, S., Vairavasundaram, S. and Vairavasundaram, I. (2023). A systematic study on reinforcement learning based applications. Energies, 16(3).
