






Introducción
La energía hidroeléctrica es la mayor fuente de electricidad de bajo carbono del mundo, suministrando cerca de un séptimo de la generación global. Además de su escala, es también uno de los recursos más flexibles en los sistemas eléctricos modernos: los grandes embalses pueden almacenar agua durante meses y liberarla bajo demanda, suavizando la variabilidad estacional y absorbiendo perturbaciones en otras partes del sistema. Esa misma capacidad de almacenamiento, sin embargo, es lo que hace del despacho hidrotérmico un problema de planificación tan difícil. Una decisión de turbinar o retener agua hoy puede no revelar su verdadero costo o valor hasta muchos meses después, y esa larga memoria debe reconciliarse con las realidades operativas del día a día, como los límites de transmisión, la disponibilidad de las plantas termoeléctricas y la creciente variabilidad de las fuentes renovables.
Durante más de tres décadas, una herramienta central para este problema ha sido la Programación Dinámica Dual Estocástica (PDDE, o SDDP en inglés), un algoritmo utilizado en estudios de planificación de la operación en países como Brasil, Bolivia, Noruega, Vietnam y Estados Unidos. En su forma clásica, el SDDP depende de dos hipótesis estructurales: la incertidumbre debe representarse de manera que preserve la independencia por etapa tras una transformación adecuada, y el problema de optimización subyacente debe ser convexo. Estas hipótesis son parte de lo que hace que el método sea tratable a escala, pero también moldean las opciones de modelización disponibles en la práctica, por ejemplo, en la forma en que se representan los procesos de caudales.
Este artículo resume un estudio reciente que explora un camino alternativo: combinar la optimización con el Aprendizaje por Refuerzo (AR) de manera que mantenga el rigor de la satisfacción de restricciones, al tiempo que relaja la hipótesis de independencia por etapa que el SDDP impone al modelo de caudales. El objetivo no es reemplazar al SDDP, que sigue siendo una referencia sólida, sino entender qué se vuelve posible cuando esa restricción estructural se relaja, y a qué costo.
Aprendizaje por Refuerzo Profundo en el contexto de los sistemas de potencia
El Aprendizaje por Refuerzo Profundo (ARP) ha experimentado una maduración excepcionalmente rápida en la última década. El campo se destacó con agentes que aprendieron a jugar videojuegos de Atari a partir de píxeles brutos, luego avanzó con AlphaGo y AlphaZero, que dominaron el Go, el ajedrez y el shogi íntegramente mediante autoaprendizaje. Más recientemente, la misma familia de técnicas se ha convertido en un ingrediente habitual en el entrenamiento de modelos de lenguaje de gran escala mediante aprendizaje por refuerzo con retroalimentación humana. Cada uno de estos hitos impulsó los algoritmos hacia adelante: métodos actor-critic eficientes en muestras como el Deep Deterministic Policy Gradient (DDPG), el Twin Delayed DDPG (TD3) y el Soft Actor-Critic (SAC), y variantes basadas en modelos que planifican sobre un modelo interno del entorno. El resultado es un conjunto de herramientas mucho más práctico, mucho más estable y mucho menos dependiente de datos de lo que estaba disponible incluso hace cinco años.
Por debajo de las variaciones algorítmicas, todos los métodos de AR comparten una estructura común: un ciclo entre un agente y un entorno. En cada paso de tiempo, el agente observa el estado del entorno y elige una acción; el entorno transita a un nuevo estado y devuelve una recompensa que evalúa la elección. Repetir este ciclo a lo largo de todo el horizonte define un episodio. El objetivo del agente es aprender una política (una regla que mapea estados observados a acciones) que maximice la recompensa acumulada a lo largo de un episodio.
Figure 1 – O framework de aprendizado por reforço
Desde el punto de vista de los sistemas de potencia, lo que hace interesante al ARP es su parentesco subyacente con los algoritmos que los operadores ya utilizan. El ARP basado en valor y el SDDP son primos sorprendentemente cercanos: ambos alternan entre un paso de simulación progresiva y una actualización retroactiva que mejora una estimativa de la función de costo futuro de largo plazo. El SDDP representa esa función con cortes convexos lineales por tramos, lo que le confiere su notable eficiencia en problemas convexos. El ARP reemplaza esos cortes con redes neuronales, que son aproximadores universales de funciones. Curiosamente, cuando la red utiliza activaciones ReLU, como la mayoría de las arquitecturas modernas, la aproximación resultante de la función de costo futuro también es lineal por tramos, pero ya no se requiere que sea convexa. En otras palabras, el ARP puede leerse como una generalización de la misma idea detrás del SDDP.
Esa generalización está comenzando a traducirse en aplicaciones concretas en sistemas de potencia. El ARP se ha utilizado para el despacho de energía en tiempo real en microrredes aisladas basadas en IoT (Lei et al., 2021), y encuestas recientes documentan una gama de casos de uso adicionales en rápido crecimiento, incluyendo la gestión de tensión y potencia reactiva en alimentadores de distribución, estrategias de oferta en mercados de electricidad, y la operación de almacenamiento en baterías en sistemas con alta penetración renovable (Sivamayil et al., 2023).
El problema de despacho hidrotérmico es otro caso de uso, marcado por un horizonte multipluranual impulsado por el acoplamiento temporal de los reservorios y por restricciones físicas rígidas en la red y en los balances hídricos. La aproximación de la función de costo futuro del ARP puede representar el valor no lineal y temporalmente acoplado del agua almacenada a lo largo de ese horizonte, pero las restricciones son un punto débil de los enfoques de AR puros. Combinar el ARP con una capa de optimización que haga cumplir esas restricciones en cada etapa es lo que hace viable este enfoque híbrido en la práctica.
El enfoque propuesto: seguimiento de objetivo con una política aprendida
El método tiene dos componentes que funcionan en conjunto. En cada etapa mensual, un problema de optimización decide qué plantas termoeléctricas e hidroeléctricas despachar, satisfaciendo el balance de carga, el balance hídrico, los límites de generación y el conjunto completo de restricciones de red. Lo que cambia es cómo se comunica el valor a largo plazo del agua almacenada al problema de etapa única. En lugar de la función de costo futuro lineal por tramos utilizada por el SDDP, un agente de AR (implementado aquí como un actor-critic DDPG) genera un volumen objetivo de embalse para cada planta hidroeléctrica, junto con un peso de penalidad que controla con qué fuerza la operación debe dirigirse hacia ese objetivo.
El problema de etapa única minimiza entonces el costo operacional inmediato más una penalidad sobre la desviación entre los volúmenes finales del embalse y los objetivos proporcionados por el agente. Si el agente recomienda mantener los embalses llenos, el agua se almacena de forma agresiva; si el agente prefiere reducir el nivel, el optimizador libera agua en la medida en que las restricciones lo permiten. El costo operacional simulado se devuelve como señal de recompensa, y las redes actor y critic se entrenan gradualmente para recomendar objetivos que minimicen el costo total a lo largo de todo el horizonte de planificación.
Dos opciones de diseño merecen destacarse. En primer lugar, la capa de optimización es la que garantiza la viabilidad: el agente de AR nunca necesita aprender qué es una restricción de red, porque el optimizador la hace cumplir para cada decisión de despacho. En segundo lugar, dividir el problema de esta manera (optimización de etapa única para la decisión inmediata, AR para el acoplamiento a largo plazo) elimina las restricciones estructurales que los solvers multiétapa normalmente imponen a la modelización. En particular, el proceso de caudales puede ser cualquier modelo que conduzca la simulación: datos históricos, un modelo de series temporales flexible, o cualquier otro proceso que consideremos que representa mejor la realidad.
La Figura 2 mapea estas piezas en una sola etapa. La entrada del agente es el estado actual $s_t$ (niveles de los embalses y rezagos de caudales recientes) junto con las incertidumbres realizadas en la etapa $\omega_t$ (caudales y demanda). Su acción tiene dos partes: un vector de volúmenes objetivo de embalse $\hat{s}{t+1}$ y un peso de penalidad $\beta_t$ que controla con qué fuerza el optimizador debe rastrear esos objetivos. La resolución del problema de rastreo de estado con estas entradas arroja el siguiente estado realizado $s{t+1}$ y el costo operacional inmediato $c_t$, que se devuelve como la señal de recompensa utilizada para entrenar al agente.
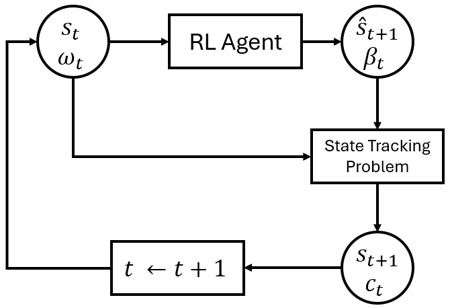
Figura 2 — Fluxo de informações entre o agente de AR e o problema de otimização de rastreamento de estado de estágio único
Estudio de caso: modelo de caudales
El enfoque propuesto se compara con el SDDP en un contexto en que las hipótesis estructurales del SDDP obligan a una simplificación de modelización que el método híbrido puede evitar: el modelo de caudales con independencia por etapa requerido por el SDDP. El sistema de prueba es el sistema eléctrico boliviano (28 barras, 11 plantas hidroeléctricas, 23 plantas termoeléctricas y 31 ramales de transmisión), simulado a lo largo de un horizonte de 5 años dividido en 60 etapas mensuales. Las políticas se comparan en los mismos 10.000 escenarios de caudales fuera de la muestra extraídos de un modelo SARIMA ajustado al historial de caudales, y cada configuración de AR se entrena cinco veces con diferentes semillas aleatorias para considerar la variabilidad derivada de la inicialización de la red neuronal.
El SDDP fue entrenado con escenarios de un modelo PAR(p), según lo exige su hipótesis de independencia por etapa. Tres variantes de AR fueron entrenadas con diferentes entradas de caudales: el propio registro histórico artificial, un generador basado en SARIMA que corresponde al proceso generador de datos fuera de la muestra y el mismo modelo PAR(p) utilizado por el SDDP.
Los resultados muestran un ordenamiento claro entre las variantes de AR. El entrenamiento con escenarios extraídos del proceso generador de datos real, incluso en número limitado, produjo costos operacionales menores que el entrenamiento con escenarios PAR(p), con una reducción de aproximadamente el 5%. La generación de un número ilimitado de escenarios SARIMA redujo aún más los costos, confirmando que los modelos de caudales flexibles combinados con datos de entrenamiento abundantes conducen a mejores políticas. El SDDP, sin embargo, terminó por delante de todas las variantes de AR, con la mejor configuración de AR quedando a aproximadamente el 5% del costo del SDDP.
Surgieron dos observaciones prácticas. En primer lugar, la hipótesis de modelización de caudales utilizada habitualmente en la planificación operacional no es inocua: reemplazar el PAR(p) por un proceso estocástico más rico cambió los costos operacionales totales en varios puntos porcentuales, manteniendo todas las demás hipótesis fijas. En segundo lugar, la variabilidad entre semillas tuvo un impacto significativo: diferentes inicializaciones condujeron a diferentes niveles de embalse al final del horizonte, lo que refuerza la importancia de evaluar múltiples semillas en cualquier implementación práctica.
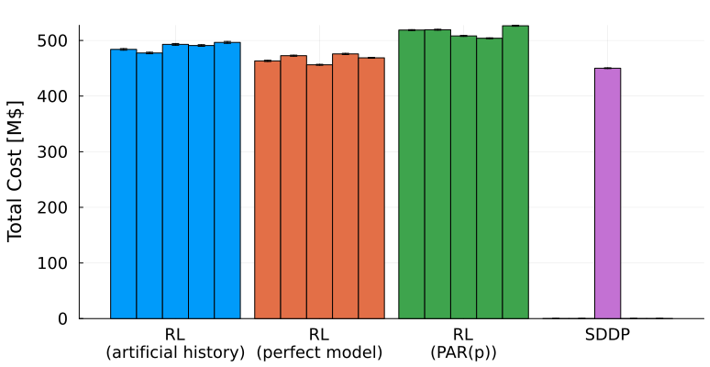
[Figura 3 — Costo operacional total para diferentes semillas aleatorias: gráfico de barras mostrando Costo Total (M$) para AR (histórico artificial), AR (modelo perfecto), AR (PAR(p)) y SDDP]
Discusión y perspectivas
Los experimentos sustentan una conclusión ponderada. Combinar optimización y Aprendizaje por Refuerzo es una forma práctica de construir políticas de despacho hidrotérmico sin imponer la hipótesis de independencia por etapa que el SDDP requiere en su modelo de caudales. El optimizador de etapa única mantiene cada restricción física viable, mientras que la política aprendida proporciona el acoplamiento temporal que el SDDP de otra forma impondría a través de su función de costo futuro lineal por tramos. Dentro de ese marco, entrenar la política con escenarios más cercanos al proceso generador de datos real redujo los costos de forma consistente entre las semillas, lo que sugiere que la restricción PAR(p) habitualmente incorporada en la planificación operacional tiene un peso económico real. La contrapartida honesta es que el SDDP siguió siendo el enfoque más costo-efectivo en las condiciones probadas. El método híbrido redujo la brecha cuando el modelo de caudales fue relajado, pero no la cerró.
Varias direcciones de investigación parecen prometedoras para explorar las ventajas potenciales del ARP. Paralelizar la optimización interna entre los escenarios mejoraría la eficiencia del entrenamiento, especialmente cuando la resolución por etapa es costosa, por ejemplo, cuando se introducen restricciones de red u operacionales más ricas. Algoritmos de AR más recientes, como el Twin Delayed DDPG y el Soft Actor-Critic, abordan algunos de los problemas de estabilidad del DDPG y podrían mejorar la eficiencia de muestras. Y dado que ya tenemos un modelo explícito dentro de la capa de optimización, el AR basado en modelos (la familia de algoritmos detrás de sistemas como el AlphaZero) es una elección natural: el agente podría evaluar varios volúmenes objetivo candidatos resolviendo el problema de etapa única para cada uno, y usar esa información para planificar con más eficacia.
El ARP en sí mismo es un conjunto de herramientas en desarrollo, y no un producto terminado. El campo ha avanzado sustancialmente en los últimos años, con algoritmos de entrenamiento más estables, mejor eficiencia de muestras e investigaciones activas sobre cómo escalar a los tipos de grandes espacios de estado y acción característicos de los sistemas de potencia. Para problemas de planificación de largo horizonte como el despacho hidrotérmico, creemos que el camino más probable es híbrido: la optimización maneja lo que hace mejor, es decir, hacer cumplir las restricciones físicas y producir decisiones tratables por etapa, mientras que el ARP maneja el acoplamiento temporal y las partes del problema que resisten la modelización convexa.
Referencias
Pereira, M.V.F. y Pinto, L.M.V.G. (1991). Multi-stage stochastic optimization applied to energy planning. Mathematical Programming, 52(1), 359–375
Rosemberg, A.W., Street, A., Garcia, J.D., Valladão, D.M., Silva, T. y Dowson, O. (2022). Assessing the cost of network simplifications in long-term hydrothermal dispatch planning models. IEEE Transactions on Sustainable Energy, 13(1), 196–206.
Lillicrap, T.P. et al. (2015). Continuous control with deep reinforcement learning. arXiv:1509.02971.
Lei, L., Tan, Y., Dahlenburg, G., Xiang, W. y Zheng, K. (2021). Dynamic energy dispatch based on deep reinforcement learning in IoT-driven smart isolated microgrids. IEEE Internet of Things Journal, 8(10), 7938–7953.
Sivamayil, K., Rajasekar, E., Aljafari, B., Nikolovski, S., Vairavasundaram, S. y Vairavasundaram, I. (2023). A systematic study on reinforcement learning based applications. Energies, 16(3).
