






Uma nova geração de modelos de linguagem de grande escala com capacidades explícitas de raciocínio mudou o que é possível no desenvolvimento de software. As ferramentas anteriores de completação de código dependiam de correspondência de padrões estatísticos e eram úteis principalmente para sugestões curtas e locais. Os modelos de raciocínio mais recentes podem decompor problemas de engenharia em etapas intermediárias, planejar uma sequência de ações, inspecionar seu próprio trabalho e iterar em direção a uma solução. Quando essa capacidade de raciocínio é incorporada em um ambiente de execução adequado, uma prática inteiramente diferente se torna disponível — aquela em que o engenheiro humano não é mais o único produtor de código, mas o arquiteto de um processo que inclui um agente de programação autônomo.
Do Transformer aos modelos de raciocínio
O caminho que leva aos agentes de programação de hoje tem raízes anteriores em décadas de trabalho em modelagem de linguagem neural, arquiteturas recorrentes e mecanismos de atenção anteriores, mas seu marco decisivo veio em 2017 com a publicação de “Attention Is All You Need” por Vaswani e colegas, a maioria deles no Google Brain e no Google Research. O artigo introduziu o Transformer, uma arquitetura de rede neural que substituiu as camadas recorrentes e convolucionais então dominantes na modelagem de linguagem por um mecanismo baseado inteiramente em autoatenção. O Transformer se mostrou excepcionalmente bem adaptado ao escalonamento, tanto em contagem de parâmetros quanto em dados de treinamento, e permanece o substrato de essencialmente todos os modelos de linguagem de grande escala lançados desde então.
A primeira onda de implicações práticas apareceu em 2018 com o GPT-1, a abordagem de pré-treinamento generativo da OpenAI, e o BERT, o codificador bidirecional do Google. Ambos estabeleceram o paradigma agora dominante de pré-treinamento em grandes corpora de texto não rotulado e, em seguida, ajuste fino em tarefas mais específicas. As diferenças entre os dois designs (somente decodificador versus somente codificador; autorregressivo versus mascarado) moldaram os diferentes caminhos de aplicação que se seguiram.
O período de 2019–2020 fez do escalonamento a questão central. O GPT-2 demonstrou que um modelo moderadamente maior treinado em mais texto produzia texto qualitativamente melhor. O GPT-3, com 175 bilhões de parâmetros, mostrou em 2020 que um maior escalonamento desbloqueava o aprendizado no contexto, a capacidade de realizar novas tarefas com apenas alguns exemplos no prompt. As leis de escalonamento publicadas no mesmo ano por Kaplan e colegas ofereceram um framework quantitativo para como a perda diminuía com os parâmetros, os dados e a computação, e moldaram grande parte dos investimentos subsequentes da área.
O ponto de inflexão de 2022 foi o alinhamento, e não a capacidade. O InstructGPT e as técnicas intimamente relacionadas por trás do ChatGPT (lançado em novembro de 2022) utilizaram o aprendizado por reforço com feedback humano (RLHF) para fazer os modelos seguirem instruções de forma confiável e recusarem solicitações claramente inadequadas. A técnica ajusta um modelo pré-treinado por meio de um modelo de recompensa que aprende com as preferências humanas sobre candidatos a completações, moldando as saídas do modelo em direção a respostas que os humanos avaliam como úteis, honestas e seguras. O avanço técnico foi modesto em termos absolutos; o avanço na experiência do usuário foi decisivo. Em meses, a tecnologia subjacente havia alcançado um público de massa.
O período de 2023–2024 viu a proliferação de provedores e a ascensão da multimodalidade. GPT-4, Claude da Anthropic, Gemini do Google e a família Llama da Meta (esta última como pesos abertos) atingiram disponibilidade geral, com a maioria adicionando compreensão de imagens, áudio ou vídeo. Ferramentas de completação de código que existiam em escalas menores desde 2021, mais notavelmente o GitHub Copilot, ganharam recursos de chat de classe GPT-4 (o Copilot Chat migrou para o GPT-4 no final de 2023), e a qualidade da assistência melhorou correspondentemente.
O próximo eixo surgiu no final de 2024 com a família de modelos de raciocínio o1 da OpenAI, seguida no início de 2025 pelo R1 da DeepSeek, o primeiro modelo de raciocínio de pesos abertos amplamente utilizado, e posteriormente, no mesmo ano, pela família o3 da OpenAI. A ideia técnica era que um modelo poderia receber mais computação no momento da resposta, e não apenas no momento do treinamento, e poderia gastar essa computação em raciocínio em cadeia de pensamento, autoavaliação e refinamento iterativo. Para tarefas envolvendo planejamento em múltiplas etapas, matemática e código, os ganhos foram substanciais. Em 2025, as principais famílias de modelos entre os provedores incluíam variantes de raciocínio. A Anthropic incorporou o pensamento estendido na família Claude, a OpenAI lançou a geração GPT-5 como uma família centrada em raciocínio, e o raciocínio se tornou uma expectativa de base, e não mais uma característica de fronteira.
A combinação de modelos de raciocínio capazes com a engenharia necessária para dotá-los de ferramentas, acesso ao sistema de arquivos e ambientes de execução produziu a onda de ferramentas de programação agênticas que definem o período atual. Ao longo de 2025, uma nova classe de agentes de linha de comando atingiu disponibilidade geral, incluindo o GitHub Copilot Agent, o Gemini CLI e o Claude Code da Anthropic, enquanto ferramentas integradas ao editor, como o Cursor, estenderam o mesmo padrão para a IDE. Em meses, a unidade de interação havia migrado da linha de código para a tarefa de engenharia.
| Era | Avanço Central | Valor Principal na Engenharia de Software |
| 2017–21 | Transformers e Escalonamento | Correspondência estatística de padrões e completação linha a linha |
| 2022–23 | Alinhamento (RLHF) e Chat | Assistência conversacional, explicação de código |
| 2024–25 | Raciocínio na Inferência | Planejamento multiestágio, cadeia de pensamento, autocorreção |
| 2025– | Scaffolding Agêntico (Harness) | Edição autônoma de arquivos, execução em CLI, integração com o Model Context Protocol (MCP) |
O arco narrativo é consistente ao longo desses marcos: a arquitetura (o Transformer) tornou o escalonamento possível; o escalonamento produziu capacidade; o alinhamento tornou a capacidade acessível; o raciocínio estendeu a capacidade para tarefas de múltiplas etapas; e o ferramental transformou os modelos resultantes em agentes de engenharia autônomos. Cada ponto de inflexão abriu a porta para o seguinte.
Modelos fundacionais e suas restrições
Por baixo de todo agente de programação está um modelo fundacional. Os principais provedores (Anthropic com Claude, OpenAI com GPT, Google com Gemini, além de um conjunto crescente de famílias de pesos abertos como Kimi K2 e Qwen 3) seguem um padrão de implantação semelhante: o modelo é treinado uma vez e, em seguida, disponibilizado com parâmetros congelados. Esse padrão acarreta uma consequência importante: o modelo em si não aprende de uma sessão para a seguinte. Ele não pode formar novas memórias permanentes, e cada nova conversa começa do zero. O que o modelo “lembra” dentro de uma sessão é limitado ao conteúdo de sua janela de contexto, a sequência delimitada de tokens que inclui o prompt do sistema, as instruções do usuário, trocas anteriores, saídas de ferramentas e o próprio raciocínio intermediário do modelo.
Cada provedor normalmente oferece seus modelos em camadas que equilibram capacidade, latência e custo. Embora a denominação específica dos fornecedores mude rapidamente, o padrão subjacente permanece um padrão do setor: um modelo principal para as tarefas de raciocínio mais difíceis (ex.: Opus da Anthropic, GPT-5 da OpenAI, Gemini Pro do Google), um modelo equilibrado para uso cotidiano (Sonnet, GPT-5 mini, Gemini Flash) e um modelo rápido e leve (Haiku, GPT-5 nano, Gemini Nano). A escolha da camada é uma decisão de engenharia de contexto, pois o raciocínio mais pesado raramente é necessário em cada etapa de uma tarefa de engenharia, e combinar a camada com a dificuldade da subtarefa é uma alavanca significativa sobre a qualidade, a latência e o custo.
As janelas de contexto modernas são grandes para os padrões históricos. As versões mais recentes do Gemini e do GPT chegam a aproximadamente um milhão de tokens; a mais recente geração de Claude atinge comprimentos comparáveis em suas configurações de contexto estendido; e modelos de pesos abertos como Kimi e Qwen ficam nas centenas de milhares. Elas permanecem finitas, porém, e dois fenômenos relacionados tornam seu gerenciamento não trivial. O primeiro é o simples truncamento que ocorre quando a janela enche: uma vez atingido o limite, o conteúdo mais antigo é descartado e o modelo perde acesso a ele. O segundo, mais sutil, é a degradação do contexto: à medida que a janela se aproxima de sua capacidade, a precisão se degrada e o modelo começa a perder o rastro de detalhes mesmo dentro do conteúdo ainda nominalmente presente. Benchmarks empíricos de recuperação de contexto longo mostram consistentemente que mais contexto nem sempre é melhor. Recentemente, a introdução do cache de prompt mitigou alguns desses pontos de atrito, permitindo que os modelos se lembrem de grandes bases de código e prompts de sistema de forma barata e rápida entre as rodadas — embora não resolva os limites fundamentais da memória de trabalho.
Essas restrições importam operacionalmente. O modelo de raciocínio tem a capacidade de planejar, escrever e verificar código, mas não tem memória persistente entre sessões nem memória de trabalho ilimitada dentro de uma sessão. A qualidade de qualquer interação estendida depende, portanto, criticamente do que é colocado dentro da janela de contexto e do que é mantido fora.
O harness do agente
Um agente de programação é mais do que o modelo fundacional que o alimenta. É um harness (conjunto de ferramentas e infraestrutura) que fornece ao modelo acesso controlado a um conjunto de ferramentas, uma forma estruturada de registrar o conhecimento do projeto e uma disciplina para gerenciar a fronteira entre planejamento e execução. Vários agentes agora competem nessa categoria, incluindo GitHub Copilot Agent, Gemini CLI, Claude Code, Cursor e Cline, e a arquitetura que compartilham é amplamente semelhante, mesmo onde o vocabulário superficial difere.
O agente opera dentro de um diretório de projeto e é equipado com um pequeno conjunto de ferramentas fundamentais: um editor de arquivos, um shell para executar testes e compilações, uma capacidade de busca e recuperação na web e uma interface de chamada de ferramentas programática. Esses primitivos permitem ao agente ler arquivos-fonte, modificá-los no local, executar a suíte de testes e consultar documentação externa — tudo sem o engenheiro sair do terminal. Dois mecanismos adicionais estendem essa base. O Model Context Protocol (MCP) é um padrão aberto, lançado pela Anthropic no final de 2024, que permite aos agentes se conectar a sistemas externos por meio de uma interface uniforme, da mesma forma que o USB-C unificou a proliferação de cabos antes dele. Embora de autoria da Anthropic, o MCP agora é adotado por uma variedade de hosts que incluem Cursor, Cline e vários agentes integrados ao editor, o que o torna uma camada de portabilidade genuína, e não um protocolo específico de um fornecedor. Um exemplo representativo é o Context7, um servidor MCP que obtém documentação atualizada e específica de versão para bibliotecas e pacotes, permitindo que o agente escreva contra a API em uso atual, e não contra a API que ele viu durante o treinamento. Habilidades (Skills) são capacidades modulares baseadas em texto, empacotadas como instruções e recursos de suporte, que o agente ativa automaticamente quando sua descrição corresponde à tarefa em questão.
Um elemento adicional dos harnesses recentes é a introdução de ferramentas estruturadas de interrogação ao usuário; implementações maduras (como o AskUserQuestion do Claude Code) permitem que o agente pause e apresente uma pergunta de múltipla escolha ao engenheiro, em vez de adivinhar um requisito ambíguo. O mecanismo é pequeno, mas consequente, porque a fonte mais frequente de trabalho desperdiçado na programação agêntica é o modelo prosseguindo confiante por uma interpretação errada de uma instrução.
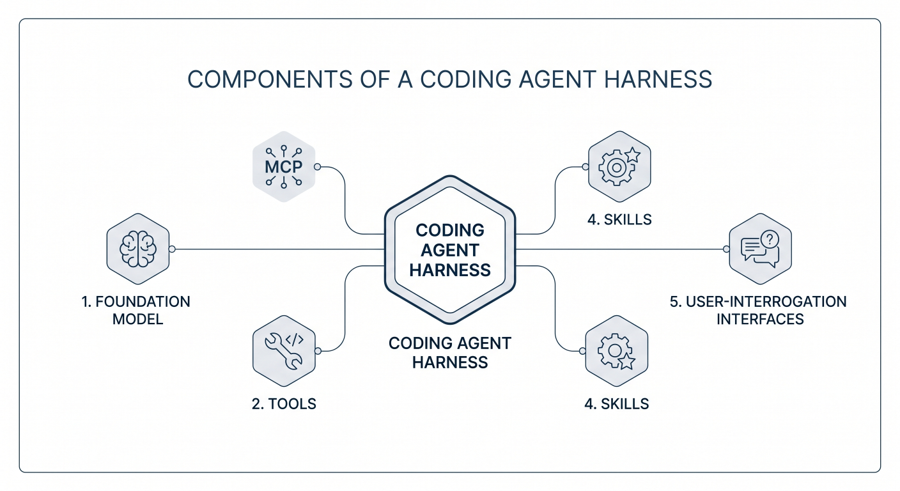
Componentes de um Harness de Agente de Programação
Duas características do harness merecem atenção especial porque abordam diretamente os problemas de memória e disciplina descritos na seção anterior. A primeira é o arquivo de memória do projeto, um documento markdown colocado na raiz do projeto que o agente lê no início de cada sessão. A convenção convergiu entre as ferramentas sob nomes diferentes: CLAUDE.md para o Claude Code, GEMINI.md para o Gemini CLI, AGENTS.md como uma convenção entre ferramentas mais recente adotada pelo Cursor, GitHub Copilot, OpenAI Codex e outros. O arquivo registra a visão geral do projeto, as convenções a seguir, os comandos que compilam e testam o código e qualquer contexto que de outra forma precisaria ser redescoberto a cada vez. É, na prática, a memória persistente que o próprio modelo não possui. Um arquivo de memória de projeto bem mantido transforma o que seria um fluxo de re-explorações idênticas em uma série de interações focadas que começam com o contexto relevante já carregado.
A segunda é a disciplina de separar o planejamento da execução, implementada sob vários nomes nas diferentes ferramentas. Nesse modo, o agente é impedido de editar arquivos ou executar comandos com efeitos colaterais; ele pode apenas ler, analisar e propor. O resultado é um plano escrito que o engenheiro revisa e aprova antes que quaisquer alterações de código ocorram. Essa separação impede o agente de se comprometer com uma direção arquitetural com a qual o humano discorda, elimina o trabalho desperdiçado em implementações prematuras e impede o modelo de cair em um “loop fatal agêntico” (agentic doom loop) — um modo de falha comum em que um modelo de raciocínio escreve repetidamente testes com falha, tenta corrigi-los e falha novamente sem intervenção humana. O princípio é simples: um agente autônomo não deve ser solto em uma tarefa desafiadora sem um plano revisado e aprovado.
Além do “vibe coding”: engenharia de prompt e de contexto
A acessibilidade dessas ferramentas produziu um estilo de desenvolvimento contrastante, às vezes chamado de vibe coding — um termo cunhado por Andrej Karpathy no início de 2025 para descrever, em suas palavras, um fluxo de trabalho em que o usuário “cede completamente à vibe”, aceita os diffs do modelo sem lê-los, cola os erros de volta sem comentários e deixa o código crescer além de sua própria compreensão. Para scripts exploratórios e protótipos descartáveis, a abordagem é genuinamente útil e reduziu a barreira para a produção de software funcional por usuários com experiência limitada em programação. Para software que precisa ser mantido, auditado e de confiança em produção, a geração de aceitar tudo produz código difícil de raciocinar, frequentemente frágil em casos extremos e exposto a vulnerabilidades de segurança que ninguém leu com atenção suficiente para detectar. A reputação da programação assistida por IA foi prejudicada correspondentemente.
A resposta profissional a esse modo de falha é a disciplina conhecida como engenharia de prompt e de contexto. A engenharia de prompt diz respeito à formulação das instruções fornecidas ao modelo: sua especificidade, sua estrutura, os limites explícitos que ela estabelece e os critérios pelos quais o sucesso será julgado. A engenharia de contexto, a prática mais ampla, diz respeito à curadoria de tudo o que o modelo vê dentro de sua janela de contexto durante uma tarefa, incluindo o prompt do sistema, o arquivo de memória do projeto, os arquivos-fonte relevantes, a conversa anterior, as definições de ferramentas e as saídas de ferramentas já invocadas. A complexidade não é eliminada; ela é transferida da interação momento a momento para um ambiente deliberadamente projetado em que o agente pode confiar.
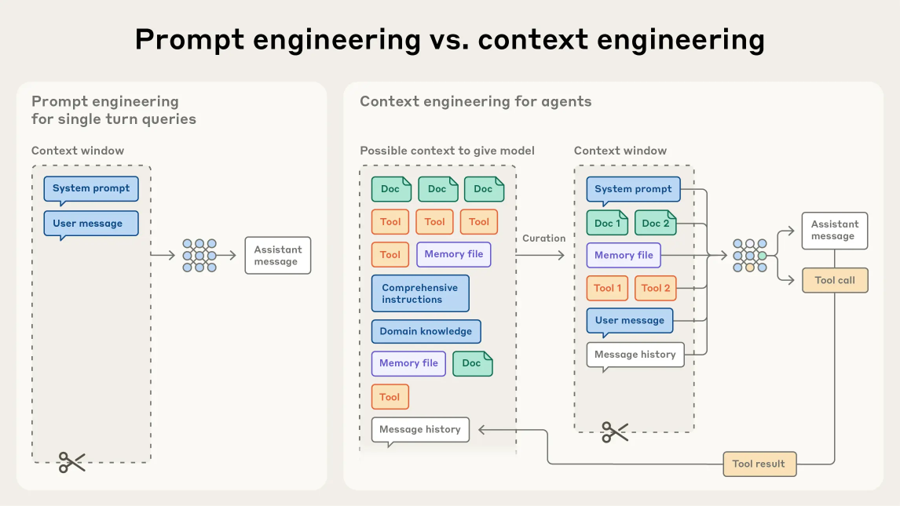
Engenharia de prompt vs. engenharia de contexto (anthropic.com/engineering/effective-context-engineering-for-ai-agents)
As implicações práticas são concretas. Uma solicitação para refatorar um módulo não é uma única frase digitada em uma caixa de chat; é um pequeno projeto que começa com o agente lendo o arquivo de memória do projeto, prossegue com uma revisão do código-fonte relevante, produz um plano que nomeia as mudanças propostas e os testes que as validarão, e somente então executa o plano em etapas, com cada etapa verificada antes que a próxima comece. Testes e cobertura de código, longe de serem preocupações secundárias, tornam-se a rede de segurança que permite que a iteração permaneça corajosa. Código gerado por IA sem cobertura rigorosa é um passivo de manutenção esperando para emergir; código gerado por IA acompanhado de uma suíte de testes robusta pode ser modificado, estendido e depurado com confiança.
De uma perspectiva de planejamento, essa mudança reformula o papel do engenheiro. A contribuição mais valiosa não é mais o volume de código escrito, mas a qualidade do contexto fornecido, a precisão dos planos aprovados e o rigor da verificação aplicada. O modelo fornece capacidade de raciocínio em uma escala que nenhum engenheiro individual pode igualar; o engenheiro fornece julgamento, conhecimento de domínio e responsabilidade pelo resultado.
Conclusões
Oito anos separam “Attention Is All You Need” dos agentes de programação autônomos agora em uso cotidiano. O caminho percorre a arquitetura Transformer, a era das leis de escalonamento, os avanços de alinhamento que tornaram o seguimento de instruções confiável, os modelos de raciocínio que estenderam a capacidade para o planejamento de múltiplas etapas e o ferramental agêntico que colocou tudo isso dentro do espaço de trabalho do engenheiro. Modelos de raciocínio capazes de planejamento de múltiplas etapas, quando combinados com um harness bem projetado que expõe ferramentas, estrutura a memória do projeto e separa o planejamento da execução, tornam possível assumir tarefas de engenharia maiores do que era prático apenas alguns anos atrás. As restrições desses modelos — em particular, a ausência de memória persistente entre sessões e a janela de contexto finita — são reais, mas gerenciáveis por meio de prática de engenharia disciplinada.
A promessa dessas ferramentas é significativa, mas apenas quando realizada por meio de engenharia de prompt e de contexto suficientemente disciplinada para ser confiável. Para organizações cujos modelos e ferramentas analíticas fundamentam decisões que importam, a implicação é direta: os próximos anos recompensarão aquelas que investirem nesse ofício com a mesma seriedade com que investiram no ofício da modelagem em si.
