






Imagine dos personas intentando llegar al mismo destino. Una tiene un auto viejo con un mapa de papel; la otra, un vehículo moderno con sistemas integrados, navegación en tiempo real, optimización de rutas y asistencia inteligente. Ambas siguen conduciendo, y ambas siguen siendo responsables de sus decisiones. Pero una de ellas se moverá más rápido, reaccionará más rápido, procesará más información y llegará al destino de forma mucho más eficiente. Eso, en esencia, es lo que la Inteligencia Artificial representa hoy. Como dijo Sam Altman, CEO de OpenAI: «La IA no reemplazará a los humanos, pero los humanos que usen IA reemplazarán a quienes no lo hagan.»
Pero el gran auto solo mejora tu experiencia de viaje; no te convierte en un buen conductor. Para realmente aprovechar la IA, el Anthropic AI Fluency Course define cuatro pasos que importan. El primero es la delegación: debes saber a dónde quieres ir y entender lo que la IA puede hacer bien. El segundo es la descripción: debes ser capaz de transmitir esa intención a la IA, dándole el rol que debe desempeñar, el contexto que debe usar y las reglas que debe seguir. Si no puedes configurar el sistema del auto e ingresar el destino en el GPS, el superauto no te ayudará. Una vez que empiezas a conducir, necesitas discernimiento: la IA sugerirá posibilidades, y tú sigues siendo responsable de verificar que la ruta que eligió es realmente la correcta para ti. ¿Cuántas veces ha elegido el GPS una ruta rápida llena de peajes, o una que simplemente no se siente segura? Con la IA, es lo mismo. El último paso es la diligencia: nunca firmes con tu nombre algo que no puedas explicar. Puedes delegar una tarea, pero nunca la comprensión que hay detrás. En nuestra analogía, puedes activar el piloto automático, pero no debes confiar en él de manera tan completa que ya no sepas cómo retomar el volante cuando algo salga mal.
En resumen, los cuatro D forman una cadena. La delegación es saber dónde ayuda la IA y dónde no. La descripción es darle el rol, el contexto y las reglas que necesita para hacer el trabajo. Estos dos pasos vienen antes de que se use el modelo. Los otros dos vienen después: el discernimiento es verificar que la ruta que la IA eligió es la correcta, que el enfoque tiene sentido y que la salida es realmente útil y correcta; y la diligencia es la conciencia de que, por bueno que sea el asistente, la firma en la respuesta final es tuya. A lo largo de este artículo, a medida que recorremos las formas en que la IA ahora se conecta a los modelos de PSR, estos cuatro pasos vale la pena tenerlos en mente: son lo que separa usar bien la IA de meramente usarla.
El uso tradicional de la IA
El primer paso lejos del mapa de papel fue el auge de los LLM. La forma más temprana de usarlos era la más simple: escribir un mensaje (un prompt), enviarlo al modelo y leer la respuesta que vuelve. ¿Cómo funciona esto en la práctica? Los LLM (Modelos de Lenguaje de Gran Escala) se entrenan en enormes conjuntos de datos textuales. Las palabras se tokenizan primero, es decir, se dividen en pequeñas piezas y se convierten en IDs numéricos que el modelo puede procesar. A partir de ese entrenamiento, el modelo aprende la probabilidad de que una palabra o frase determinada siga a otra en un contexto dado y usa esas probabilidades para generar nuevo contenido bajo demanda. Eso es lo que llamamos IA generativa. Produce correos electrónicos, resúmenes, fragmentos de código y borradores de informes. El resultado es genuinamente útil, pero sí tiene limitaciones.
Un LLM genérico está limitado por el conjunto de datos en el que fue entrenado, y reentrenar un modelo es lo suficientemente costoso como para que no pueda hacerse en tiempo real. La consecuencia es la falta de contexto. Si le preguntas a la IA sobre algo específico de PSR que no formaba parte de su entrenamiento, no lo admite; adivina, y lo que es peor, lo hace con total confianza. Pregúntale, por ejemplo, «¿qué es una estación renovable en SDDP?» y el modelo responderá usando información pública sobre el concepto físico de plantas renovables, algo así como: «Una Estación Renovable es una instalación de generación de energía que produce electricidad a partir de fuentes de energía naturalmente renovables, como la solar, la eólica, la hídrica o la biomasa.» Eso es lo que llamamos alucinación.
Inteligencia fundamentada: un asistente que conoce PSR
Para cerrar esa falta de contexto, el LLM debe de alguna manera acceder al propio conocimiento de PSR. Dado que reentrenar completamente el modelo con la documentación de PSR sería costoso, imagine que en cambio podemos conectar una memoria USB al LLM en el momento en que necesita ser respondido. La técnica que hace exactamente eso es la Generación Aumentada por Recuperación (RAG). Funciona en cuatro pequeños pasos. Primero, la documentación de PSR (manuales, notas metodológicas, ejemplos) se divide en piezas más pequeñas llamadas chunks, se tokeniza y se incorpora en un índice vectorial, de modo que habla el mismo lenguaje numérico que el LLM usa para generar texto (0). Cuando un usuario hace una pregunta (1), la pregunta misma también se vectoriza, y una búsqueda por similitud usando distancia de coseno devuelve los pasajes cuyo significado está más cercano a ella. Esos pasajes se inyectan en el prompt como contexto, para que el LLM reciba tanto la pregunta del usuario como la documentación que necesita para responderla correctamente, exactamente el paso de descripción del que hablamos en el párrafo de apertura (2). El LLM luego compone una respuesta fundamentada a partir de esa evidencia, y no de su entrenamiento general (3).
El PSR Assistant utiliza exactamente esta técnica para que los usuarios hagan preguntas específicas sobre PSR. No solo responde la pregunta; también devuelve el enlace a la página relevante en el PSR Knowledge Hub, para que el usuario pueda verificar la información. Más allá de evitar las alucinaciones, la ganancia real es el tiempo: en lugar de buscar en cientos de páginas, el usuario obtiene una respuesta directa con fuente. El Assistant tiene dos «hermanos» construidos sobre el mismo patrón, pero fundamentados en el código fuente de las bibliotecas de PSR: uno para PSR Factory, nuestra API de automatización en Python, y otro para PSRIO, nuestra herramienta de BI. Para los usuarios que aún no dominan esas bibliotecas, resuelven el problema de la página en blanco: basta con pedir un script típico y obtener un punto de partida funcional que se puede adaptar.
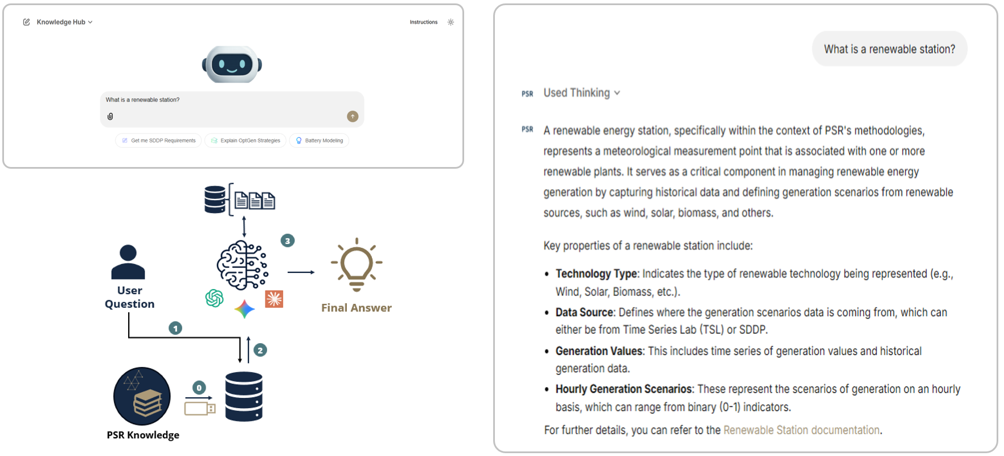
Figura 1 — El RAG ancla el LLM en la propia documentación de PSR, reemplazando definiciones alucinadas por respuestas fundamentadas con fuentes.
IA agéntica: de respuestas a acciones
Pero ¿y si la IA pudiera ir más allá de generar contenido y comenzar a ejecutar tareas? Imagine que el trabajo manual que un analista realiza todos los días — descubrir los datos de entrada de un modelo, editar esos datos, ejecutar casos en las instalaciones o en la nube, visualizar los resultados — pudiera convertirse en tareas automatizadas activadas por una única solicitud en lenguaje natural. Este es el tercer paso del viaje: de la IA generativa a la IA agéntica, un sistema diseñado para ejecutar flujos de trabajo complejos combinando planificación autónoma, memoria a largo plazo y la capacidad de interactuar con aplicaciones externas. Pero si el LLM todavía tiene datos limitados, ¿cómo puede saber sobre nuestros datos?
Las plataformas de IA modernas, de OpenAI, Anthropic y otras, ahora admiten ramificaciones personalizadas que dan al modelo acceso a aplicaciones externas. El modelo se comporta entonces como un orquestador: utiliza esas ramificaciones, junto con su propio LLM, para ejecutar tareas para el usuario. Para ejecutar una tarea automáticamente, el modelo necesita acceso a una función de código personalizada que pueda invocar y que, a su vez, pueda acceder a fuentes de datos externas. La forma estándar de hacer esta conexión es el Model Context Protocol (MCP), un protocolo abierto que permite que cualquier LLM interactúe con sistemas externos a través de una interfaz consistente. Un servidor MCP publica un catálogo de herramientas — funciones tipadas, cada una con una descripción clara — que el modelo puede navegar e invocar. El PSR Agent es nuestro servidor MCP. Expone funciones que, a través de la API Python de PSR Factory, se comunican con las bases de datos de los modelos PSR. La orquestación generalmente comienza con un plan interno de lo que debe hacerse; el modelo luego compara este plan con las descripciones en el catálogo de herramientas, por similitud, y selecciona la herramienta que mejor corresponde a la tarea en cuestión.
Para que la IA realice todo esto bien, necesita una buena descripción de cómo funcionan estas herramientas y qué flujo de trabajo debe utilizarse para cada tarea. Pero sería tedioso escribir esas instrucciones desde cero cada vez. La solución natural es empaquetarlas una vez y reutilizarlas. Esta es la idea detrás de las Habilidades (Skills): paquetes de instrucciones, ejemplos y scripts auxiliares que el agente carga bajo demanda cuando reconoce un tipo de tarea familiar. Donde el MCP le da acceso a la IA, las Habilidades le dan experiencia: el orden correcto en que invocar las herramientas, las trampas comunes que evitar, el estilo PSR para informar resultados. A continuación se ilustra un flujo de trabajo típico; al final del mismo, el LLM se usa una vez más, esta vez para redactar el resultado o para reportar un mensaje de éxito o fracaso.
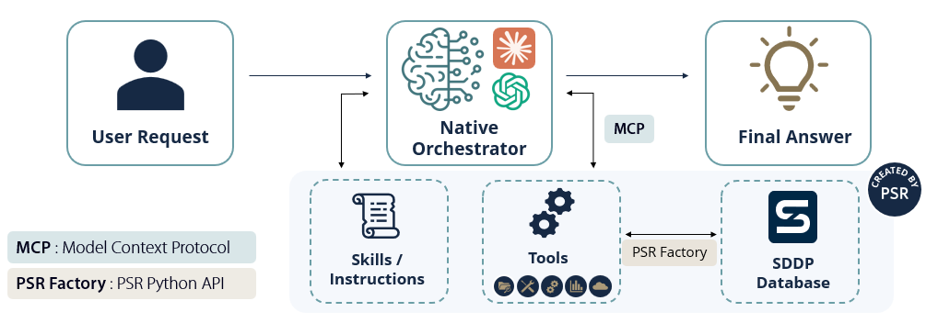
Figura 2 — El PSR Agent: un modelo de IA usa su LLM para descubrir y cargar Habilidades para experiencia de dominio, accede a las herramientas PSR a través del MCP y lee y escribe en la base de datos SDDP vía PSR Factory.
El conjunto de herramientas que PSR incorporó al Agent está centrado en las partes del día que más tiempo consumen. Localizar un objeto, navegar por sus relaciones o filtrar elementos por condición se convierte en una sola pregunta, en lugar de una secuencia de pestañas y clics a través de la interfaz. Las operaciones en masa repetitivas — actualizar capacidades, escalar series temporales, crear nuevos objetos — pueden ejecutarse automáticamente en un modo de copia segura que preserva el caso original. Las simulaciones en SDDP, OptGen y NCP pueden lanzarse directamente desde la conversación, con el Agent monitoreando el estado de ejecución y extrayendo resúmenes estructurados de errores, advertencias e información de convergencia de los registros de ejecución. Las comparaciones de escenarios, los cálculos de ingresos y los análisis de resultados también pueden realizarse a través de la conversación; una sola instrucción es suficiente para empaquetar las salidas y notificar al equipo.
En resumen, el conjunto actual de herramientas fue diseñado para reducir el trabajo operacional repetitivo realizado tradicionalmente a través de la interfaz gráfica. El proyecto está previsto para evolucionar de forma incremental: a medida que se identifiquen nuevos flujos de trabajo recurrentes y necesidades de los usuarios, se incorporarán capacidades adicionales al Agent con el tiempo.
En la práctica, un solo prompt como «actualice la capacidad instalada de la Planta X a 1.350 MW, ejecute SDDP para el horizonte de 2026 y envíe los resultados por correo electrónico al equipo de operaciones» ya corresponde a un flujo de trabajo que anteriormente requería varios pasos manuales en diferentes interfaces. El usuario todavía revisa las acciones propuestas y valida la respuesta final, pero la fricción operacional cae drásticamente.
El próximo paso: una capa de razonamiento
Fundamentar el LLM en el conocimiento de PSR y conectarlo a las herramientas de PSR cubre las partes de «información» y «ejecución» del problema. La tercera pieza, aún en desarrollo, es la capa de análisis: un agente que no solo responde preguntas o ejecuta tareas operacionales bajo demanda, sino que interpreta los resultados de las simulaciones, formula hipótesis sobre lo que los está impulsando y obtiene los datos necesarios para probar esas hipótesis.
El prototipo, actualmente en desarrollo, está estructurado como un pipeline multiagente. Un orquestador despacha la solicitud del usuario a subagentes especializados — uno para clasificación del problema, uno para hipótesis de causa, uno para descubrimiento de datos — cada uno con su propio conjunto restringido de herramientas. El orquestador luego combina sus salidas en una única respuesta sintetizada, con evidencia rastreable que el analista puede auditar paso a paso.
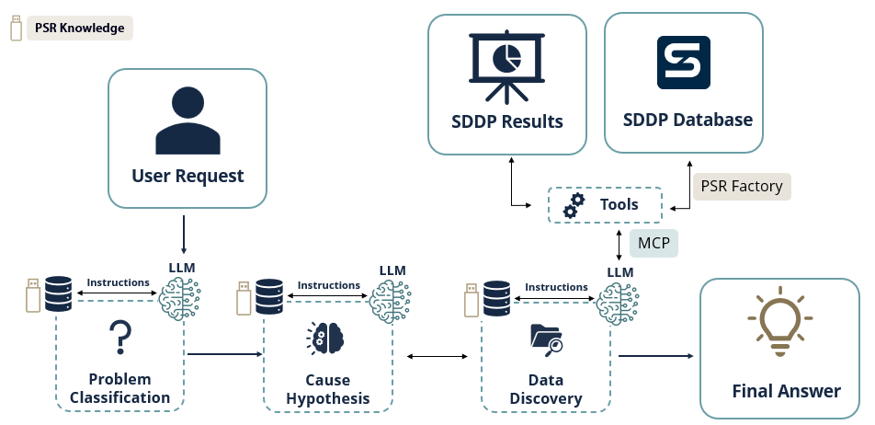
Figura 3 — Agente de razonamiento en desarrollo: subagentes especializados clasifican el problema, generan hipótesis y descubren datos, devolviendo una respuesta analítica sintetizada con respaldo de evidencias.
En conjunto, RAG, IA agéntica y la capa de razonamiento trazan un camino claro para la IA dentro de PSR: de explicar los modelos, a operarlos, a razonar sobre sus resultados. El objetivo no es reemplazar al analista, sino quitarle el trabajo rutinario de sus manos, para que el tiempo ahorrado se dedique a lo que realmente requiere juicio humano.
