






Introdução
Muitos dos problemas analíticos que definem os sistemas de energia modernos são, em seu núcleo computacional, grandes problemas de otimização. O despacho econômico, o comprometimento de unidades (unit commitment), o planejamento da expansão, a operação estocástica, a avaliação de confiabilidade e os fluxos de trabalho de planejamento baseados em decomposição dependem fortemente de programação matemática. À medida que os sistemas incorporam mais variabilidade renovável, tecnologias de armazenamento, detalhamento de rede e representações de incerteza baseadas em cenários, o tamanho desses problemas de otimização cresce mais rapidamente do que os fluxos de trabalho tradicionais foram projetados para absorver.
Este é o contexto da parceria técnica entre a PSR e a NVIDIA: avaliar como os algoritmos baseados em GPU podem ser usados para resolver problemas de otimização em larga escala que surgem em análises reais de sistemas de energia. O foco não é simplesmente executar um modelo existente em um dispositivo mais rápido. É entender quais classes de algoritmos de otimização se beneficiam da arquitetura GPU, onde os gargalos práticos se movem e como isso muda a escala dos problemas que podem ser resolvidos dentro dos orçamentos de tempo operacionais ou de planejamento.
A programação linear é um ponto de partida natural para essa investigação. Os PLs aparecem diretamente em modelos de despacho e indiretamente dentro de fluxos de trabalho maiores: como relaxações de problemas de inteiros mistos, como subproblemas em métodos de decomposição, como blocos de cenários em modelos estocásticos e como resoluções repetidas dentro de ferramentas de planejamento de longo prazo. No próprio ecossistema de software da PSR, isso inclui modelos construídos em JuMP, formulações de despacho econômico para operadores de sistema e esquemas de decomposição nos quais muitos PLs relacionados precisam ser resolvidos ou verificados repetidamente.
Por mais de duas décadas, o progresso na resolução de grandes PLs dependeu tanto de algoritmos quanto de hardware. O paradigma dominante para a solução de PLs de alta qualidade em larga escala tem sido o método de ponto interior (IPM), que hoje é usado principalmente em CPUs. Mais recentemente, os métodos de gradiente híbrido primal-dual de primeira ordem (PDLP) surgiram como uma alternativa viável para problemas muito grandes. Em vez de resolver sistemas de Newton dispendiosos, esses métodos dependem principalmente de produtos esparsos matriz-vetor — uma operação que se mapeia naturalmente na arquitetura massivamente paralela das GPUs modernas.
Este artigo discute a motivação para solvers de PL baseados em GPU, os tipos de problemas de otimização de sistemas de energia em que eles podem ser especialmente relevantes e um benchmark desenvolvido com o NVIDIA cuOpt, a biblioteca de otimização em GPU da NVIDIA. O benchmark é um estudo de caso concreto: mostra como os algoritmos baseados em GPU se comportam em um grande PL de despacho estruturado e o que isso sugere para fluxos de trabalho mais amplos de análise energética.
Por que GPUs para grandes PLs?
Dois paradigmas algorítmicos são especialmente relevantes para PLs de larga escala:
- Métodos de ponto interior (IPMs): Esses continuam sendo a abordagem dominante para muitos PLs de larga escala em CPUs. Cada iteração exige a solução de um sistema esparso de Newton ou KKT, tornando a álgebra linear esparsa o principal gargalo computacional. Implementações de IPM aceleradas por GPU estão começando a surgir, mas as fatorações esparsas para as matrizes irregulares comuns na otimização de sistemas de energia permanecem difíceis de paralelizar eficientemente.
- Métodos primal-dual de primeira ordem (PDLP): Esses métodos formam uma classe mais recente de solvers nos quais cada iteração é dominada por produtos esparsos matriz-vetor. Eles evitam a fatoração, e suas operações principais se paralelizam naturalmente em GPUs. A contrapartida é que a convergência pode ser sensível ao condicionamento do problema e à tolerância solicitada.
A questão prática é se, para PLs de escala industrial, um solver de GPU de primeira ordem pode fornecer uma aceleração significativa em relação a um IPM de CPU de alta qualidade, ainda produzindo soluções com a qualidade exigida para uso analítico e operacional. A resposta depende do tamanho do problema, do condicionamento numérico, dos requisitos de tolerância e do fluxo de trabalho circundante. As GPUs são mais atraentes quando o modelo é grande o suficiente para manter o dispositivo ocupado e quando a maior parte do trabalho computacional pode ser expresso como álgebra linear esparsa repetida.
A instância de benchmark
Para tornar a discussão concreta, consideramos um modelo de despacho econômico dia a frente do Sistema Interligado Nacional (SIN), operado pelo ONS. O modelo é formulado como um programa linear de larga escala, sem variáveis binárias de comprometimento de unidades. Ele representa recursos térmicos, renováveis, hídricos e de armazenamento, com suas características operacionais capturadas por parâmetros como volumes de reservatório, afluências, limites de rampas e eficiências de conversão. A rede de transmissão é modelada usando uma formulação de fluxo de potência CC baseada em ângulos, enquanto os links HVDC são representados como injeções de potência controláveis.
Nessa formulação, os ângulos de tensão dos barramentos são variáveis de decisão explícitas, e os fluxos nas linhas são vinculados às diferenças de ângulo pelas equações linearizadas da rede CC. Essa representação é esparsa e direta, tornando-a um benchmark útil para avaliar como os métodos de primeira ordem baseados em GPU lidam com os grandes PLs estruturados que surgem em aplicações de despacho.
Metodologia
O benchmark compara um solver de ponto interior em CPU com o solver PDLP em GPU no NVIDIA cuOpt. Os dois solvers pertencem a diferentes famílias algorítmicas e foram configurados com suas tolerâncias padrão respectivas.
A linha de base de CPU é o solver de ponto interior HiGHS, um IPM de código aberto amplamente utilizado. O solver de GPU é o NVIDIA cuOpt, configurado com suas tolerâncias de convergência padrão para infeasibilidade primal relativa, infeasibilidade dual relativa e gap de dualidade relativo. Os experimentos foram realizados na arquitetura NVIDIA Grace Blackwell. Nas execuções de CPU, apenas a CPU hospedeira é usada. Nas execuções de GPU, o PL é resolvido na GPU após o pré-solve. A métrica reportada é o tempo de solução no lado do solver: a fase IPM para a linha de base de CPU e a fase PDLP para o cuOpt.
Para investigar o regime de escalonamento, o PL de despacho foi executado em cinco comprimentos de horizonte — 1, 2, 4, 12 e 24 horas — usando os mesmos dados de rede e recursos. O caso de 24 horas é o tamanho operacionalmente relevante, enquanto os horizontes mais curtos ajudam a identificar o ponto em que a vantagem da GPU começa a dominar. A instância de 24 horas atinge 757 mil linhas, 1,42 milhão de colunas e 2,75 milhões de não-zeros.
Principais resultados
O benchmark produz um padrão claro de escalonamento, resumido na Figura 1.
Primeiro, na instância operacionalmente relevante de 24 horas, o solver PDLP em GPU é aproximadamente três vezes mais rápido do que a linha de base IPM HiGHS. O cuOpt resolve o PL de 757 mil linhas em 464 segundos, em comparação com 1.400 segundos para o HiGHS — uma aceleração de 3,0×. No horizonte de 12 horas, a aceleração é de 1,8× (172 s vs. 312 s). Os dois solvers concordam no objetivo com um gap relativo de aproximadamente $10^{-3}$ em cada instância resolvida por ambos os métodos, o que é consistente com a tolerância padrão de primeira ordem. A comparação, portanto, aponta para uma vantagem computacional genuína no regime de grandes instâncias, ao mesmo tempo em que deixa claro que verificações de viabilidade e resíduo permanecem importantes ao traduzir soluções de primeira ordem para uso operacional.
Segundo, a vantagem da GPU aparece à medida que o problema cresce. Abaixo do horizonte de 12 horas, o PL ainda é pequeno o suficiente para que o IPM de CPU permaneça competitivo ou mais rápido: no horizonte de 1 hora, o HiGHS leva 3,3 s vs. 14,2 s para o cuOpt, e em 2 e 4 horas os dois solvers estão dentro de um fator relativamente pequeno. Esse comportamento é consistente com os algoritmos subjacentes. As iterações do PDLP são individualmente baratas e compostas quase inteiramente por produtos esparsos matriz-vetor, mas o problema deve ser grande o suficiente para amortizar os custos fixos de inicialização da GPU e de movimentação de dados antes que o paralelismo compense.
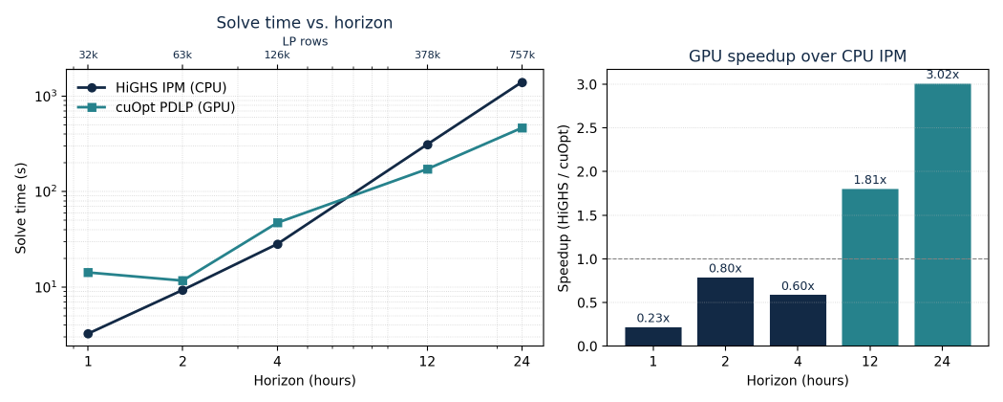
Figura 1 — Tempo de solução (esquerda, log-log) e aceleração da GPU (direita) vs. comprimento do horizonte para o PL de despacho brasileiro. O IPM de CPU (HiGHS) vence nas menores instâncias; o solver PDLP em GPU (cuOpt) assume acima do horizonte de 4 horas e alcança uma vantagem de 3× na instância de 24 horas com 757 mil linhas.
O que um despacho PL mais rápido possibilita
Uma aceleração em um único PL de despacho é útil isoladamente, mas as implicações operacionais são mais amplas do que o número principal sugere. Os modelos de despacho são resolvidos muitas vezes por dia e frequentemente estão incorporados em fluxos de trabalho iterativos de planejamento, avaliação de segurança e análise de incerteza.
Três usos concretos da resolução mais rápida se destacam:
Redespacho mais frequente: Na operação intradiária, o PL é resolvido novamente à medida que as previsões e as condições do sistema mudam. Um tempo de solução mais rápido pode encurtar o ciclo de redespacho, melhorando a capacidade de resposta a erros de previsão e eventos não planejados.
- Mais cenários em fluxos de trabalho estocásticos e robustos: O despacho estocástico e o planejamento consciente da incerteza multiplicam o PL determinístico por muitos cenários. Uma resolução por cenário mais rápida pode se traduzir quase diretamente em mais cenários dentro do mesmo orçamento de tempo de relógio.
- Maior fidelidade do modelo: PLs mais rápidos tornam mais prático incluir contingências adicionais, discretização temporal mais fina e representações de rede mais detalhadas sem ultrapassar o orçamento de tempo operacional.
A implicação mais ampla é que a aceleração por GPU é mais valiosa quando o problema de despacho permanece em um grande PL estruturado. Muitas extensões operacionais e de planejamento preservam essa estrutura: cenários adicionais, resolução temporal mais fina, representação de armazenamento mais detalhada e detalhamento de rede mais rico podem todos aumentar o tamanho do problema sem necessariamente alterar a classe matemática do modelo. Nesse contexto, a questão relevante não é apenas se um PL resolve mais rápido, mas se o solver torna um fluxo de trabalho analítico maior prático dentro do mesmo orçamento de tempo.
Discussão e conclusões
O benchmark responde a uma questão prática dentro de uma direção de pesquisa mais ampla: um solver de PL de primeira ordem em GPU pode fornecer uma aceleração significativa em um PL de sistema de energia com formato de produção? Para essa classe de problema, a resposta é sim. No PL de despacho dia a frente brasileiro com uma formulação de rede CC baseada em ângulos, o PDLP do cuOpt no hardware NVIDIA de geração atual resolve a instância de 24 horas aproximadamente três vezes mais rápido do que o método de ponto interior de CPU HiGHS (464 segundos vs. 1.400 segundos), com ambos os solvers relatando uma solução ótima e correspondendo aos valores objetivos dentro da tolerância padrão de primeira ordem.
Duas qualificações são importantes. Primeiro, a aceleração da GPU não domina em todos os tamanhos de problema. Em PLs pequenos, a sobrecarga do host pode superar os benefícios do paralelismo, e o IPM de CPU continua sendo a melhor escolha. A vantagem da GPU se materializa uma vez que o problema seja grande o suficiente para manter o dispositivo efetivamente utilizado. Segundo, o PDLP é um método de primeira ordem e é sensível ao condicionamento e aos requisitos de tolerância. Atingir tolerâncias significativamente mais rígidas do que o padrão pode ser um regime computacional diferente, em que os métodos de ponto interior retêm uma vantagem estrutural. Isso significa que o valor do PDLP baseado em GPU deve ser avaliado em relação ao nível de precisão exigido pelo fluxo de trabalho, não apenas pelo tempo bruto de solução.
A conclusão principal é que os algoritmos baseados em GPU podem alterar o envelope computacional para otimização em larga escala em análises energéticas. Eles não substituem os métodos de ponto interior de CPU em todos os regimes, mas fornecem uma alternativa sólida quando o modelo é grande, esparso e dominado por operações que as GPUs podem executar eficientemente. Isso importa porque muitas das melhorias de modelagem mais relevantes no setor aumentam o tamanho do PL, em vez de alterar a estrutura matemática fundamental do problema. Soluções mais rápidas dessa camada central podem, portanto, apoiar estudos mais detalhados, mais frequentemente repetidos e mais ricos em cenários, mantendo a computação dentro dos limites práticos.
Para a PSR e a NVIDIA, o significado do resultado não é apenas a aceleração específica reportada em um benchmark de despacho. É a evidência de que os algoritmos de PL baseados em GPU estão se tornando relevantes para as cargas de trabalho de otimização reais por trás do planejamento e da operação de sistemas de energia. À medida que os modelos continuam a crescer em resolução temporal, detalhamento espacial e representação de incerteza, a capacidade de explorar a arquitetura GPU se tornará uma parte cada vez mais importante do conjunto de ferramentas de otimização.
