






Introduction
Many of the analytical problems that define modern power systems are, at their computational core, large optimization problems. Economic dispatch, unit-commitment, expansion planning, stochastic operation, reliability assessment, and decomposition-based planning workflows all rely heavily on mathematical programming. As systems incorporate more renewable variability, storage technologies, network detail, and scenario-based representations of uncertainty, the size of these optimization problems is growing faster than traditional workflows were designed to absorb.
This is the context for the technical partnership between PSR and NVIDIA: evaluating how GPU-based algorithms can be used to solve large-scale optimization problems that arise in real power-system analytics. The focus is not simply to run an existing model on a faster device. It is to understand which classes of optimization algorithms benefit from GPU architecture, where the practical bottlenecks move, and how this changes the scale of problems that can be solved within operational or planning time budgets.
Linear programming is a natural starting point for this investigation. LPs appear directly in dispatch models and indirectly inside larger workflows: as relaxations of mixed-integer problems, as subproblems in decomposition methods, as scenario blocks in stochastic models, and as repeated solves inside long-term planning tools. In PSR’s own software ecosystem, this includes models built in JuMP, economic dispatch formulations for system operators, and decomposition schemes in which many related LPs must be solved or checked repeatedly.
For more than two decades, progress in solving large LPs has depended as much on algorithms as on hardware. The dominant paradigm for high-quality large-scale LP solution has been the interior-point method (IPM), which today is used primarily on CPUs. More recently, first-order primal-dual hybrid gradient methods (PDLP) have emerged as a credible alternative for very large problems. Instead of solving expensive Newton systems, these methods rely mainly on sparse matrix-vector products, an operation that maps naturally onto the massively parallel architecture of modern GPUs.
This article discusses the motivation for GPU-powered LP solvers, the types of power-system optimization problems where they may be especially relevant, and a benchmark developed with NVIDIA cuOpt, NVIDIA’s GPU optimization library. The benchmark is a concrete case study: it shows how GPU-based algorithms behave on a large, structured dispatch LP and what that suggests for broader energy-analytics workflows.
Why GPUs for large LPs?
Two algorithmic paradigms are especially relevant for large-scale LPs:
- Interior-point methods (IPMs): These remain the dominant approach for many large-scale LPs on CPUs. Each iteration requires the solution of a sparse Newton or KKT system, making sparse linear algebra the main computational bottleneck. GPU-accelerated IPM implementations are beginning to emerge, but sparse factorizations for the irregular matrices common in power-system optimization remain challenging to parallelize efficiently.
- First-order primal-dual methods (PDLP): These methods form a more recent class of solvers in which each iteration is dominated by sparse matrix-vector products. They avoid factorization, and their core operations parallelize naturally on GPUs. The trade-off is that convergence can be sensitive to problem conditioning and to the requested tolerance.
The practical question is whether, for industrial-scale LPs, a first-order GPU solver can deliver a meaningful speed-up over a high-quality CPU IPM while still producing solutions of the quality required for analytical and operational use. The answer depends on problem size, numerical conditioning, tolerance requirements, and the surrounding workflow. GPUs are most attractive when the model is large enough to keep the device busy and when most of the computational work can be expressed as repeated sparse linear algebra.
The benchmark instance
To make the discussion concrete, we consider a day-ahead economic dispatch model of the Brazilian Interconnected System (SIN), operated by ONS. The model is formulated as a large-scale linear program, with no unit commitment binary variables. It represents thermal, renewable, hydro, and storage resources, with their operational characteristics captured through parameters such as reservoir volumes, inflows, ramping limits, and conversion efficiencies. The transmission network is modeled using an angle-based DC power flow formulation, while HVDC links are represented as controllable power injections.
In this formulation, bus voltage angles are explicit decision variables, and line flows are linked to angle differences through the linearized DC network equations. This representation is sparse and direct, making it a useful benchmark for evaluating how GPU-based first-order methods handle the large but structured LPs that arise in dispatch applications.
Methodology
The benchmark compares a CPU interior-point solver with the GPU PDLP solver in NVIDIA cuOpt. The two solvers belong to different algorithmic families and were configured at their respective default tolerances.
The CPU baseline is the HiGHS interior-point solver, a widely used open-source IPM. The GPU solver is NVIDIA cuOpt, configured at its default convergence tolerances for relative primal infeasibility, relative dual infeasibility, and relative duality gap. Experiments were performed on NVIDIA Grace Blackwell architecture. In the CPU runs, only the host CPU is used. In the GPU runs, the LP is solved on the GPU after presolve. The reported metric is solver-side solve time: the IPM phase for the CPU baseline and the PDLP phase for cuOpt.
To probe the scaling regime, the dispatch LP was run at five horizon lengths – 1, 2, 4, 12, and 24 hours – using the same network and resource data. The 24-hour case is the operationally relevant size, while the shorter horizons help identify the point at which the GPU advantage begins to dominate. The 24-hour instance reaches 757k rows, 1.42M columns, and 2.75M non-zeros.
Key results
The benchmark produces a clear scaling pattern, summarized in Figure 1.
First, on the operationally relevant 24-hour instance, the GPU PDLP solver is roughly three times faster than the HiGHS IPM baseline. cuOpt solves the 757k-row LP in 464 seconds, compared with 1,400 seconds for HiGHS, a 3.0x speed-up. At the 12-hour horizon, the speed-up is 1.8x (172 s vs. 312 s). The two solvers agree on the objective within roughly a $10^{-3}$ relative gap on every instance solved by both methods, which is consistent with the default first-order tolerance. The comparison therefore points to a genuine computational advantage in the large-instance regime, while also making clear that feasibility and residual checks remain important when translating first-order solutions into operational use.
Second, the GPU advantage appears as the problem grows. Below the 12-hour horizon, the LP is still small enough for the CPU IPM to remain competitive or faster: at 1 hour horizon, HiGHS takes 3.3 s versus 14.2 s for cuOpt, and at 2 and 4 hours the two solvers are within a relatively small factor. This behavior is consistent with the underlying algorithms. PDLP iterations are individually inexpensive and composed almost entirely of sparse matrix-vector products, but the problem must be large enough to amortize fixed GPU launch and data-movement costs before the parallelism pays off.
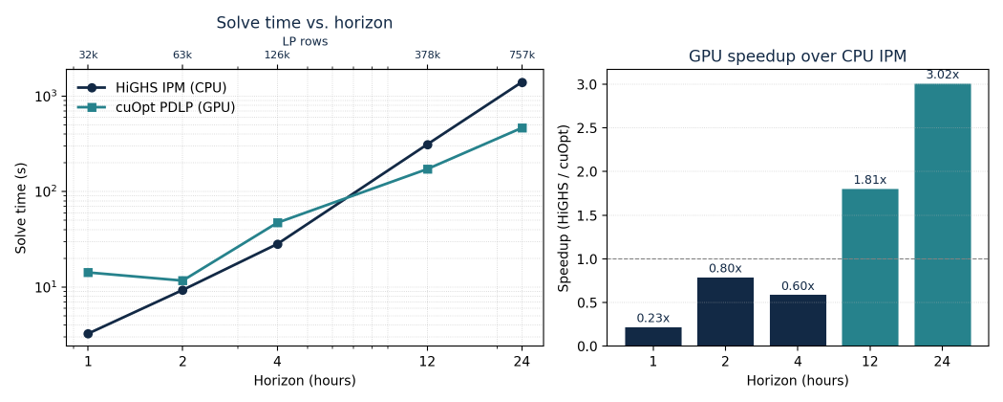
Figure 1 – Solve time (left, log–log) and GPU speed-up (right) vs. horizon length for the Brazilian dispatch LP. The CPU IPM (HiGHS) wins on the smallest instances; the GPU PDLP solver (cuOpt) takes over above the 4-hour horizon and reaches a 3 times advantage on the 24-hour, 757k-row instance.
What a faster dispatch LP enables
A speed-up on a single dispatch LP is useful in isolation, but the operational implications are broader than the headline number suggests. Dispatch models are solved many times per day and are often embedded inside iterative planning, security assessment, and uncertainty-analysis workflows.
Three concrete uses of the faster solve stand out:
More frequent re-dispatch: In intraday operation, the LP is re-solved as forecasts and system conditions change. A faster solve time can shorten the re-dispatch cycle, improving responsiveness to forecast errors and unplanned events.
- More scenarios in stochastic and robust workflows: Stochastic dispatch and uncertainty-aware planning multiply the deterministic LP across many scenarios. A faster per-scenario solve can translate almost directly into more scenarios within the same wall-clock budget.
- Higher model fidelity: Faster LPs make it more practical to include additional contingencies, finer time discretization, and more detailed network representations without exceeding the operational time budget.
The broader implication is that GPU acceleration is most valuable when the dispatch problem remains in a large, structured LP. Many operational and planning extensions preserve that structure: additional scenarios, finer temporal resolution, more detailed storage representation, and richer network detail can all increase problem size without necessarily changing the mathematical class of the model. In that setting, the relevant question is not only whether one LP solves faster, but whether the solver makes a larger analytical workflow practical within the same time budget.
Discussion and conclusions
The benchmark answers a practical question within a broader research direction: can a GPU first-order LP solver deliver a meaningful speed-up on a production-shaped power-system LP? For this class of problem, the answer is yes. On the Brazilian day-ahead dispatch LP with an angle-based DC network formulation, cuOpt PDLP on current-generation NVIDIA hardware solves the 24-hour instance roughly three times faster than the HiGHS CPU interior-point method (464 seconds vs. 1400 seconds), with both solvers reporting an optimal solution and matching objective values within the default first-order tolerance.
Two qualifications are important. First, GPU acceleration does not dominate across all problem sizes. On small LPs, host overhead can outweigh the benefits of parallelism, and the CPU IPM remains the better choice. The GPU advantage materializes once the problem is large enough to keep the device effectively utilized. Second, PDLP is a first-order method and is sensitive to conditioning and tolerance requirements. Reaching tolerances significantly tighter than the default may be a different computational regime, where interior-point methods retain a structural advantage. This means the value of GPU-based PDLP should be assessed in relation to the accuracy level required by the workflow, not only by raw solve time.
The main conclusion is that GPU-based algorithms can change the computational envelope for large-scale optimization in energy analytics. They do not replace CPU interior-point methods in every regime, but they provide a strong alternative when the model is large, sparse, and dominated by operations that GPUs can execute efficiently. This matters because many of the most relevant modeling improvements in the sector increase LP size rather than changing the fundamental structure of the problem. Faster solutions of this core layer can therefore support more detailed, more frequently repeated, and more scenario-rich studies while keeping computation within practical limits.
For PSR and NVIDIA, the significance of the result is not only the specific speed-up reported in one dispatch benchmark. It is evidence that GPU-powered LP algorithms are becoming relevant to the real optimization workloads behind power-system planning and operation. As models continue to grow in temporal resolution, spatial detail, and uncertainty representation, the ability to exploit GPU architecture will become an increasingly important part of the optimization toolbox.
