






Introducción
Muchos de los problemas analíticos que definen los sistemas eléctricos modernos son, en su núcleo computacional, grandes problemas de optimización. El despacho económico, el compromiso de unidades (unit commitment), la planificación de la expansión, la operación estocástica, la evaluación de confiabilidad y los flujos de trabajo de planificación basados en descomposición dependen en gran medida de la programación matemática. A medida que los sistemas incorporan más variabilidad renovable, tecnologías de almacenamiento, detalle de red y representaciones de incertidumbre basadas en escenarios, el tamaño de estos problemas de optimización crece más rápido de lo que los flujos de trabajo tradicionales fueron diseñados para absorber.
Este es el contexto de la asociación técnica entre PSR y NVIDIA: evaluar cómo los algoritmos basados en GPU pueden usarse para resolver problemas de optimización a gran escala que surgen en análisis reales de sistemas de energía. El foco no es simplemente ejecutar un modelo existente en un dispositivo más rápido. Es comprender qué clases de algoritmos de optimización se benefician de la arquitectura GPU, dónde se desplazan los cuellos de botella prácticos y cómo esto cambia la escala de los problemas que pueden resolverse dentro de los presupuestos de tiempo operacionales o de planificación.
La programación lineal es un punto de partida natural para esta investigación. Los PL aparecen directamente en modelos de despacho e indirectamente dentro de flujos de trabajo más grandes: como relajaciones de problemas de enteros mixtos, como subproblemas en métodos de descomposición, como bloques de escenarios en modelos estocásticos y como resoluciones repetidas dentro de herramientas de planificación a largo plazo. En el propio ecosistema de software de PSR, esto incluye modelos construidos en JuMP, formulaciones de despacho económico para operadores de sistema y esquemas de descomposición en los que muchos PL relacionados deben resolverse o verificarse repetidamente.
Durante más de dos décadas, el progreso en la resolución de grandes PL ha dependido tanto de los algoritmos como del hardware. El paradigma dominante para la solución de PL a gran escala de alta calidad ha sido el método de punto interior (IPM), que hoy se usa principalmente en CPU. Más recientemente, los métodos de gradiente híbrido primal-dual de primer orden (PDLP) han surgido como una alternativa viable para problemas muy grandes. En lugar de resolver costosos sistemas de Newton, estos métodos dependen principalmente de productos de matrices-vectores dispersos, una operación que se mapea naturalmente en la arquitectura masivamente paralela de las GPU modernas.
Este artículo analiza la motivación para los solvers de PL basados en GPU, los tipos de problemas de optimización de sistemas de energía en los que pueden ser especialmente relevantes, y un benchmark desarrollado con NVIDIA cuOpt, la biblioteca de optimización en GPU de NVIDIA. El benchmark es un estudio de caso concreto: muestra cómo los algoritmos basados en GPU se comportan en un PL de despacho grande y estructurado, y qué sugiere eso para flujos de trabajo más amplios de análisis energético.
¿Por qué GPU para grandes PL?
Dos paradigmas algorítmicos son especialmente relevantes para los PL a gran escala:
- Métodos de punto interior (IPM): Estos siguen siendo el enfoque dominante para muchos PL a gran escala en CPU. Cada iteración requiere la solución de un sistema de Newton o KKT disperso, lo que convierte al álgebra lineal dispersa en el principal cuello de botella computacional. Las implementaciones de IPM aceleradas por GPU están comenzando a surgir, pero las factorizaciones dispersas para las matrices irregulares habituales en la optimización de sistemas de energía siguen siendo difíciles de paralelizar eficientemente.
- Métodos primal-dual de primer orden (PDLP): Estos métodos forman una clase más reciente de solvers en los que cada iteración está dominada por productos de matrices-vectores dispersos. Evitan la factorización, y sus operaciones principales se paralelizan naturalmente en GPU. La contrapartida es que la convergencia puede ser sensible al condicionamiento del problema y a la tolerancia solicitada.
La pregunta práctica es si, para PL de escala industrial, un solver de GPU de primer orden puede ofrecer una aceleración significativa sobre un IPM de CPU de alta calidad, produciendo al mismo tiempo soluciones con la calidad requerida para el uso analítico y operacional. La respuesta depende del tamaño del problema, el condicionamiento numérico, los requisitos de tolerancia y el flujo de trabajo circundante. Las GPU son más atractivas cuando el modelo es lo suficientemente grande como para mantener el dispositivo ocupado y cuando la mayor parte del trabajo computacional puede expresarse como álgebra lineal dispersa repetida.
La instancia de benchmark
Para hacer la discusión concreta, consideramos un modelo de despacho económico del día siguiente del Sistema Interconectado Nacional (SIN) brasileño, operado por ONS. El modelo se formula como un programa lineal a gran escala, sin variables binarias de compromiso de unidades. Representa recursos térmicos, renovables, hídricos y de almacenamiento, con sus características operacionales capturadas a través de parámetros como volúmenes de embalse, caudales, límites de rampas y eficiencias de conversión. La red de transmisión se modela usando una formulación de flujo de potencia CC basada en ángulos, mientras que los enlaces HVDC se representan como inyecciones de potencia controlables.
En esta formulación, los ángulos de tensión de los nodos son variables de decisión explícitas, y los flujos en las líneas se vinculan a las diferencias de ángulo a través de las ecuaciones linearizadas de la red CC. Esta representación es dispersa y directa, lo que la convierte en un benchmark útil para evaluar cómo los métodos de primer orden basados en GPU manejan los grandes PL estructurados que surgen en las aplicaciones de despacho.
Metodología
El benchmark compara un solver de punto interior en CPU con el solver PDLP en GPU del NVIDIA cuOpt. Los dos solvers pertenecen a diferentes familias algorítmicas y fueron configurados con sus tolerancias predeterminadas respectivas.
La línea de base de CPU es el solver de punto interior HiGHS, un IPM de código abierto ampliamente utilizado. El solver de GPU es NVIDIA cuOpt, configurado con sus tolerancias de convergencia predeterminadas para infeasibilidad primal relativa, infeasibilidad dual relativa y brecha de dualidad relativa. Los experimentos se realizaron en la arquitectura NVIDIA Grace Blackwell. En las ejecuciones de CPU, solo se usa la CPU anfitriona. En las ejecuciones de GPU, el PL se resuelve en la GPU después del pre-procesamiento. La métrica reportada es el tiempo de resolución del lado del solver: la fase IPM para la línea de base de CPU y la fase PDLP para el cuOpt.
Para investigar el régimen de escalamiento, el PL de despacho se ejecutó en cinco longitudes de horizonte — 1, 2, 4, 12 y 24 horas — usando los mismos datos de red y recursos. El caso de 24 horas es el tamaño operacionalmente relevante, mientras que los horizontes más cortos ayudan a identificar el punto en que la ventaja de la GPU comienza a dominar. La instancia de 24 horas alcanza 757.000 filas, 1,42 millones de columnas y 2,75 millones de no-ceros.
Resultados clave
El benchmark produce un patrón de escalamiento claro, resumido en la Figura 1.
En primer lugar, en la instancia operacionalmente relevante de 24 horas, el solver PDLP en GPU es aproximadamente tres veces más rápido que la línea de base IPM HiGHS. cuOpt resuelve el PL de 757.000 filas en 464 segundos, en comparación con 1.400 segundos para HiGHS, una aceleración de 3,0×. En el horizonte de 12 horas, la aceleración es de 1,8× (172 s vs. 312 s). Los dos solvers coinciden en el objetivo con una brecha relativa de aproximadamente $10^{-3}$ en cada instancia resuelta por ambos métodos, lo que es consistente con la tolerancia predeterminada de primer orden. La comparación apunta, por lo tanto, a una ventaja computacional genuina en el régimen de grandes instancias, al tiempo que deja claro que las verificaciones de viabilidad y residuos siguen siendo importantes al trasladar soluciones de primer orden al uso operacional.
En segundo lugar, la ventaja de la GPU aparece a medida que el problema crece. Por debajo del horizonte de 12 horas, el PL es todavía lo suficientemente pequeño como para que el IPM de CPU siga siendo competitivo o más rápido: en el horizonte de 1 hora, HiGHS tarda 3,3 s frente a 14,2 s para cuOpt, y en 2 y 4 horas los dos solvers están dentro de un factor relativamente pequeño. Este comportamiento es consistente con los algoritmos subyacentes. Las iteraciones del PDLP son individualmente baratas y compuestas casi íntegramente por productos de matrices-vectores dispersos, pero el problema debe ser lo suficientemente grande para amortizar los costos fijos de lanzamiento de GPU y movimiento de datos antes de que el paralelismo compense.
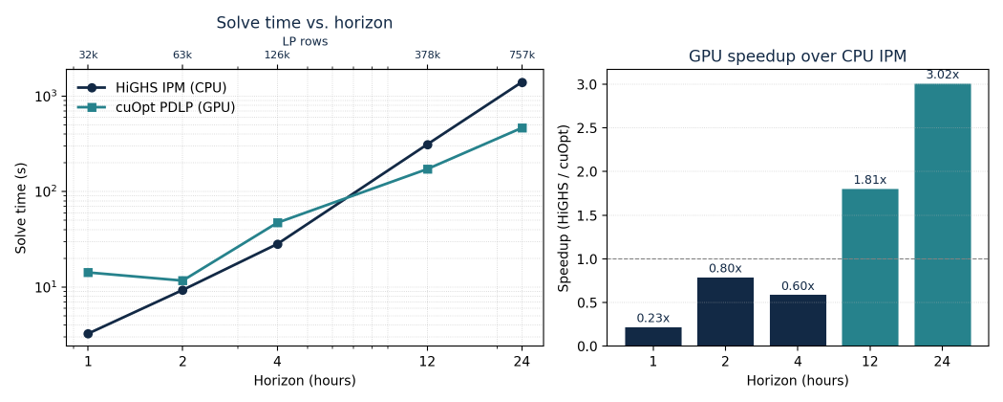
Figura 1 — Tempo de solução (esquerda, log-log) e aceleração da GPU (direita) vs. comprimento do horizonte para o PL de despacho brasileiro. O IPM de CPU (HiGHS) vence nas menores instâncias; o solver PDLP em GPU (cuOpt) assume acima do horizonte de 4 horas e alcança uma vantagem de 3× na instância de 24 horas com 757 mil linhas.
Lo que habilita un despacho PL más rápido
Una aceleración en un único PL de despacho es útil en aislamiento, pero las implicaciones operacionales son más amplias que el número principal sugiere. Los modelos de despacho se resuelven muchas veces al día y frecuentemente están incorporados dentro de flujos de trabajo iterativos de planificación, evaluación de seguridad y análisis de incertidumbre.
Tres usos concretos de la resolución más rápida se destacan:
Redespacho más frecuente: En la operación intradiaria, el PL se resuelve nuevamente a medida que los pronósticos y las condiciones del sistema cambian. Un tiempo de resolución más rápido puede acortar el ciclo de redespacho, mejorando la capacidad de respuesta a los errores de pronóstico y a los eventos no planificados.
- Más escenarios en flujos de trabajo estocásticos y robustos: El despacho estocástico y la planificación consciente de la incertidumbre multiplican el PL determinístico a lo largo de muchos escenarios. Una resolución por escenario más rápida puede traducirse casi directamente en más escenarios dentro del mismo presupuesto de tiempo de reloj.
- Mayor fidelidad del modelo: Los PL más rápidos hacen más práctico incluir contingencias adicionales, discretización temporal más fina y representaciones de red más detalladas sin superar el presupuesto de tiempo operacional.
La implicación más amplia es que la aceleración de GPU es más valiosa cuando el problema de despacho permanece en un PL grande y estructurado. Muchas extensiones operacionales y de planificación preservan esa estructura: escenarios adicionales, resolución temporal más fina, representación de almacenamiento más detallada y mayor detalle de red pueden aumentar el tamaño del problema sin cambiar necesariamente la clase matemática del modelo. En ese contexto, la pregunta relevante no es solo si un PL se resuelve más rápido, sino si el solver hace que un flujo de trabajo analítico más grande sea práctico dentro del mismo presupuesto de tiempo.
Discusión y conclusiones
El benchmark responde a una pregunta práctica dentro de una dirección de investigación más amplia: ¿puede un solver de PL de primer orden en GPU ofrecer una aceleración significativa en un PL de sistema de energía con formato de producción? Para esta clase de problema, la respuesta es sí. En el PL de despacho del día siguiente brasileño con una formulación de red CC basada en ángulos, el PDLP de cuOpt en hardware NVIDIA de generación actual resuelve la instancia de 24 horas aproximadamente tres veces más rápido que el método de punto interior de CPU HiGHS (464 segundos vs. 1.400 segundos), con ambos solvers reportando una solución óptima y valores objetivos coincidentes dentro de la tolerancia predeterminada de primer orden.
Dos calificaciones son importantes. En primer lugar, la aceleración de GPU no domina en todos los tamaños de problema. En PL pequeños, la sobrecarga del host puede superar los beneficios del paralelismo, y el IPM de CPU sigue siendo la mejor elección. La ventaja de la GPU se materializa una vez que el problema es lo suficientemente grande como para mantener el dispositivo efectivamente utilizado. En segundo lugar, el PDLP es un método de primer orden y es sensible al condicionamiento y a los requisitos de tolerancia. Alcanzar tolerancias significativamente más ajustadas que las predeterminadas puede ser un régimen computacional diferente, en el que los métodos de punto interior retienen una ventaja estructural. Esto significa que el valor del PDLP basado en GPU debe evaluarse en relación con el nivel de precisión requerido por el flujo de trabajo, y no solo por el tiempo bruto de resolución.
La conclusión principal es que los algoritmos basados en GPU pueden cambiar el envolvente computacional para la optimización a gran escala en el análisis energético. No reemplazan los métodos de punto interior de CPU en todos los regímenes, pero proporcionan una alternativa sólida cuando el modelo es grande, disperso y dominado por operaciones que las GPU pueden ejecutar eficientemente. Esto importa porque muchas de las mejoras de modelización más relevantes en el sector aumentan el tamaño del PL en lugar de cambiar la estructura matemática fundamental del problema. Las soluciones más rápidas de esta capa central pueden, por lo tanto, respaldar estudios más detallados, más frecuentemente repetidos y más ricos en escenarios, manteniendo la computación dentro de los límites prácticos.
Para PSR y NVIDIA, la relevancia del resultado no es solo la aceleración específica reportada en un benchmark de despacho. Es la evidencia de que los algoritmos de PL basados en GPU están volviéndose relevantes para las cargas de trabajo de optimización reales que sustentan la planificación y la operación de sistemas de energía. A medida que los modelos continúan creciendo en resolución temporal, detalle espacial y representación de incertidumbre, la capacidad de explotar la arquitectura GPU se convertirá en una parte cada vez más importante del conjunto de herramientas de optimización.
