






Una nueva generación de modelos de lenguaje de gran escala con capacidades explícitas de razonamiento ha cambiado lo que es posible en el desarrollo de software. Las herramientas anteriores de completación de código dependían de la correspondencia de patrones estadísticos y eran útiles principalmente para sugerencias cortas y locales. Los modelos de razonamiento más recientes pueden descomponer problemas de ingeniería en pasos intermedios, planificar una secuencia de acciones, inspeccionar su propio trabajo e iterar hacia una solución. Cuando esta capacidad de razonamiento se incorpora en un entorno de ejecución adecuado, una práctica completamente diferente se vuelve disponible: aquella en la que el ingeniero humano ya no es el único productor de código, sino el arquitecto de un proceso que incluye un agente de programación autónomo.
Del Transformer a los modelos de razonamiento
El camino que lleva a los agentes de programación de hoy tiene raíces anteriores en décadas de trabajo en modelización de lenguaje neuronal, arquitecturas recurrentes y mecanismos de atención anteriores, pero su hito decisivo llegó en 2017 con la publicación de «Attention Is All You Need» por Vaswani y colegas, la mayoría de ellos en Google Brain y Google Research. El artículo introdujo el Transformer, una arquitectura de red neuronal que reemplazó las capas recurrentes y convolucionales entonces dominantes en la modelización de lenguaje por un mecanismo basado íntegramente en autoatención. El Transformer resultó ser excepcionalmente adecuado para el escalamiento, tanto en conteo de parámetros como en datos de entrenamiento, y ha permanecido como el sustrato de prácticamente todos los modelos de lenguaje de gran escala publicados desde entonces.
La primera ola de implicaciones prácticas apareció en 2018 con el GPT-1, el enfoque de preentrenamiento generativo de OpenAI, y el BERT, el codificador bidireccional de Google. Ambos establecieron el paradigma ahora dominante de preentrenamiento en grandes corpus de texto no etiquetado y luego ajuste fino en tareas más específicas. Las diferencias entre los dos diseños (solo decodificador versus solo codificador; autorregresivo versus enmascarado) moldearon los divergentes caminos de aplicación que siguieron.
El período 2019–2020 convirtió el escalamiento en la cuestión central. El GPT-2 demostró que un modelo moderadamente más grande entrenado en más texto producía texto cualitativamente mejor. El GPT-3, con 175 mil millones de parámetros, mostró en 2020 que un mayor escalamiento desbloqueaba el aprendizaje en contexto, la capacidad de realizar nuevas tareas con solo unos pocos ejemplos en el prompt. Las leyes de escalamiento publicadas el mismo año por Kaplan y colegas ofrecieron un marco cuantitativo sobre cómo la pérdida disminuía con los parámetros, los datos y el cómputo, y moldearon gran parte de la inversión posterior del campo.
El punto de inflexión de 2022 fue el alineamiento, y no la capacidad. El InstructGPT y las técnicas estrechamente relacionadas detrás del ChatGPT (lanzado en noviembre de 2022) utilizaron el aprendizaje por refuerzo con retroalimentación humana (RLHF) para hacer que los modelos siguieran instrucciones de forma confiable y rechazaran solicitudes claramente inapropiadas. La técnica ajusta un modelo preentrenado a través de un modelo de recompensa que aprende de las preferencias humanas sobre candidatos a completaciones, moldeando las salidas del modelo en dirección a respuestas que los humanos califican como útiles, honestas y seguras. El avance técnico fue modesto en términos absolutos; el avance en la experiencia del usuario fue decisivo. En meses, la tecnología subyacente había alcanzado a un público masivo.
El período 2023–2024 vio la proliferación de proveedores y el auge de la multimodalidad. GPT-4, Claude de Anthropic, Gemini de Google y la familia Llama de Meta (esta última como pesos abiertos) alcanzaron disponibilidad general, con la mayoría añadiendo comprensión de imágenes, audio o video. Las herramientas de completación de código que habían existido a escalas menores desde 2021, más notablemente el GitHub Copilot, adquirieron características de chat de clase GPT-4 (Copilot Chat migró a GPT-4 a fines de 2023), y la calidad de la asistencia mejoró correspondientemente.
El siguiente eje apareció a fines de 2024 con la familia de modelos de razonamiento o1 de OpenAI, seguida a principios de 2025 por el R1 de DeepSeek, el primer modelo de razonamiento de pesos abiertos ampliamente utilizado, y más tarde ese año por la familia o3 de OpenAI. La idea técnica era que un modelo podría recibir más cómputo en el momento de responder, y no solo en el momento del entrenamiento, y podría gastar ese cómputo en razonamiento en cadena de pensamiento, autoverificación y refinamiento iterativo. Para tareas que involucran planificación de múltiples pasos, matemáticas y código, las ganancias fueron sustanciales. Para 2025, las principales familias de modelos entre los proveedores incluían variantes de razonamiento. Anthropic incorporó el pensamiento extendido en la familia Claude, OpenAI lanzó la generación GPT-5 como una familia centrada en el razonamiento, y el razonamiento se había convertido en una expectativa de base y no en una característica de frontera.
La combinación de modelos de razonamiento capaces con la ingeniería necesaria para dotarlos de herramientas, acceso al sistema de archivos y entornos de ejecución produjo la ola de herramientas de programación agénticas que definen el período actual. A lo largo de 2025, una nueva clase de agentes de línea de comandos alcanzó disponibilidad general, incluyendo el GitHub Copilot Agent, Gemini CLI y Claude Code de Anthropic, mientras que herramientas integradas al editor, como Cursor, extendieron el mismo patrón al IDE. En meses, la unidad de interacción había migrado de la línea de código a la tarea de ingeniería.
| Era | Avance Central | Valor Principal en la Ingeniería de Software |
| 2017–21 | Transformers y Escalamiento | Correspondencia estadística de patrones y completación línea a línea |
| 2022–23 | Alineamiento (RLHF) y Chat | Asistencia conversacional, explicación de código |
| 2024–25 | Razonamiento en la Inferencia | Planificación multiétapa, cadena de pensamiento, autocorrección |
| 2025– | Scaffolding Agéntico (Harness) | Edición autónoma de archivos, ejecución en CLI, integración con Model Context Protocol (MCP) |
El arco narrativo es consistente a lo largo de estos hitos: la arquitectura (el Transformer) hizo posible el escalamiento; el escalamiento produjo capacidad; el alineamiento hizo la capacidad accesible; el razonamiento extendió la capacidad hacia tareas de múltiples pasos; y el herramental convirtió los modelos resultantes en agentes de ingeniería autónomos. Cada punto de inflexión abrió la puerta al siguiente.
Modelos fundacionales y sus restricciones
Por debajo de todo agente de programación hay un modelo fundacional. Los principales proveedores (Anthropic con Claude, OpenAI con GPT, Google con Gemini, más un conjunto creciente de familias de pesos abiertos como Kimi K2 y Qwen 3) siguen un patrón de implementación similar: el modelo se entrena una vez y luego se sirve con parámetros congelados. Este patrón conlleva una consecuencia importante: el modelo en sí no aprende de una sesión a la siguiente. No puede formar nuevos recuerdos permanentes, y cada nueva conversación comienza desde cero. Lo que el modelo «recuerda» dentro de una sesión está limitado al contenido de su ventana de contexto, la secuencia delimitada de tokens que incluye el prompt del sistema, las instrucciones del usuario, intercambios anteriores, salidas de herramientas y el propio razonamiento intermedio del modelo.
Cada proveedor típicamente ofrece sus modelos en niveles que equilibran capacidad, latencia y costo. Aunque la denominación específica de los proveedores cambia rápidamente, el patrón subyacente sigue siendo un estándar de la industria: un modelo principal para las tareas de razonamiento más difíciles (ej.: Opus de Anthropic, GPT-5 de OpenAI, Gemini Pro de Google), un modelo equilibrado para uso cotidiano (Sonnet, GPT-5 mini, Gemini Flash) y un modelo rápido y ligero (Haiku, GPT-5 nano, Gemini Nano). La elección del nivel es una decisión de ingeniería de contexto, ya que el razonamiento más pesado rara vez se necesita en cada paso de una tarea de ingeniería y hacer coincidir el nivel con la dificultad de la subtarea es una palanca significativa sobre la calidad, la latencia y el costo.
Las ventanas de contexto modernas son grandes para los estándares históricos. Las versiones más recientes de Gemini y GPT alcanzan aproximadamente un millón de tokens, la última generación de Claude alcanza longitudes comparables en sus configuraciones de contexto extendido, y los modelos de pesos abiertos como Kimi y Qwen se sitúan en las centenas de miles bajas. Sin embargo, permanecen finitas, y dos fenómenos relacionados hacen que su gestión no sea trivial. El primero es el simple truncamiento que ocurre cuando la ventana se llena: una vez alcanzado el límite, el contenido más antiguo se descarta y el modelo pierde acceso a él. El segundo, más sutil, es la degradación del contexto: a medida que la ventana se aproxima a su capacidad, la precisión se degrada y el modelo comienza a perder el rastro de detalles incluso dentro del contenido aún nominalmente presente. Los benchmarks empíricos de recuperación de contexto largo muestran consistentemente que más contexto no siempre es mejor. Recientemente, la introducción del caché de prompt ha mitigado algunos de estos puntos de fricción al permitir que los modelos recuerden grandes bases de código y prompts de sistema de forma barata y rápida entre las rondas, aunque no resuelve los límites fundamentales de la memoria de trabajo.
Estas restricciones importan operacionalmente. El modelo de razonamiento tiene la capacidad de planificar, escribir y verificar código, pero no tiene memoria persistente entre sesiones ni memoria de trabajo ilimitada dentro de una sesión. La calidad de cualquier interacción extendida depende, por lo tanto, críticamente de lo que se coloca dentro de la ventana de contexto y de lo que se mantiene fuera.
El harness del agente
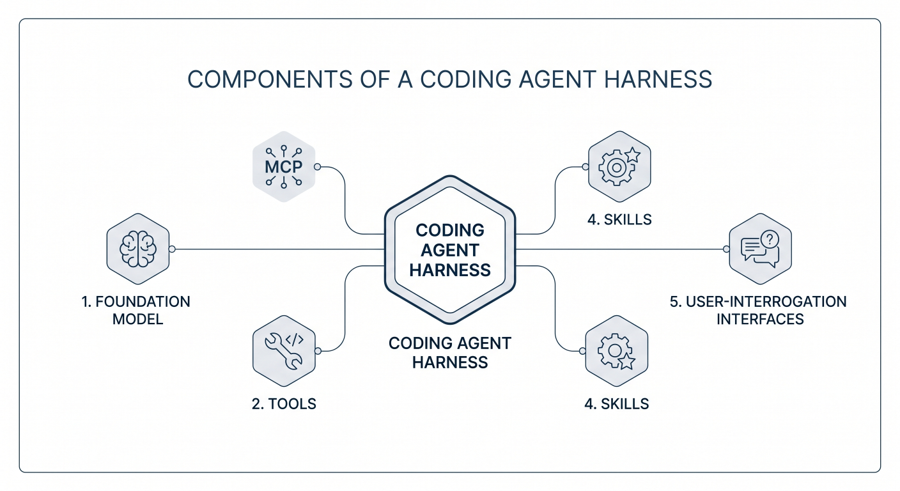
Un agente de programación es más que el modelo fundacional que lo alimenta. Es un harness que proporciona al modelo acceso controlado a un conjunto de herramientas, una forma estructurada de registrar el conocimiento del proyecto y una disciplina para gestionar la frontera entre planificación y ejecución. Varios agentes compiten ahora en esta categoría, incluyendo GitHub Copilot Agent, Gemini CLI, Claude Code, Cursor y Cline, y la arquitectura que comparten es ampliamente similar incluso donde el vocabulario superficial difiere.
El agente opera dentro de un directorio de proyecto y está equipado con un pequeño conjunto de herramientas fundamentales: un editor de archivos, un shell para ejecutar pruebas y compilaciones, una capacidad de búsqueda y recuperación en la web y una interfaz de llamada de herramientas programática. Estos primitivos permiten al agente leer archivos fuente, modificarlos en su lugar, ejecutar la suite de pruebas y consultar documentación externa, todo sin que el ingeniero salga del terminal. Dos mecanismos adicionales amplían esta base. El Model Context Protocol (MCP) es un estándar abierto, lanzado por Anthropic a fines de 2024, que permite a los agentes conectarse a sistemas externos a través de una interfaz uniforme, de la misma forma que el USB-C unificó la proliferación de cables antes de él. Aunque de autoría de Anthropic, el MCP es ahora adoptado por una variedad de hosts que incluyen Cursor, Cline y varios agentes integrados al editor, lo que lo convierte en una capa de portabilidad genuina en lugar de un protocolo específico de un proveedor. Un ejemplo representativo es Context7, un servidor MCP que obtiene documentación actualizada y específica de versión para bibliotecas y paquetes, permitiendo al agente escribir contra la API en uso actual en lugar de la API que vio durante el entrenamiento. Las Habilidades (Skills) son capacidades modulares basadas en texto, empaquetadas como instrucciones y recursos de apoyo, que el agente activa automáticamente cuando su descripción coincide con la tarea en cuestión.
Un elemento adicional de los harnesses recientes es la introducción de herramientas estructuradas de interrogación al usuario; implementaciones maduras (como el AskUserQuestion del Claude Code) permiten al agente hacer una pausa y plantear una pregunta de opción múltiple al ingeniero en lugar de adivinar un requisito ambiguo. El mecanismo es pequeño pero consecuente, porque la fuente más frecuente de trabajo desperdiciado en la programación agéntica es el modelo que avanza con confianza por una interpretación errónea de una instrucción.
Componentes de um Harness de Agente de Programação
Dos características del harness merecen atención especial porque abordan directamente los problemas de memoria y disciplina descritos en la sección anterior. La primera es el archivo de memoria del proyecto, un documento markdown colocado en la raíz del proyecto que el agente lee al inicio de cada sesión. La convención ha convergido entre las herramientas bajo diferentes nombres: CLAUDE.md para Claude Code, GEMINI.md para Gemini CLI, AGENTS.md como una convención entre herramientas más reciente adoptada por Cursor, GitHub Copilot, OpenAI Codex y otros. El archivo registra la visión general del proyecto, las convenciones a seguir, los comandos que compilan y prueban el código y cualquier contexto que de otra forma tendría que redescubrirse cada vez. Es, en efecto, la memoria persistente que el propio modelo no tiene. Un archivo de memoria de proyecto bien mantenido transforma lo que sería un flujo de re-exploraciones idénticas en una serie de interacciones enfocadas que comienzan con el contexto relevante ya cargado.
La segunda es la disciplina de separar la planificación de la ejecución, implementada bajo varios nombres en las diferentes herramientas. En este modo, se impide al agente editar archivos o ejecutar comandos con efectos secundarios; solo puede leer, analizar y proponer. El resultado es un plan escrito que el ingeniero revisa y aprueba antes de que ocurra cualquier cambio de código. Esta separación impide al agente comprometerse con una dirección arquitectónica con la que el humano no está de acuerdo, elimina el trabajo desperdiciado en implementaciones prematuras y evita que el modelo caiga en un «loop fatal agéntico» (agentic doom loop), un modo de falla común en el que un modelo de razonamiento escribe repetidamente pruebas fallidas, intenta corregirlas y falla de nuevo sin intervención humana. El principio es sencillo: no se debe lanzar un agente autónomo a una tarea desafiadora sin un plan revisado y aprobado.
Más allá del «vibe coding»: ingeniería de prompt y de contexto
La accesibilidad de estas herramientas ha producido un estilo de desarrollo contrastante a veces denominado vibe coding, un término acuñado por Andrej Karpathy a principios de 2025 para describir, en sus palabras, un flujo de trabajo en el que el usuario «cede completamente a las vibraciones», acepta los diffs del modelo sin leerlos, pega los errores de vuelta sin comentarios y deja que el código crezca más allá de su propia comprensión. Para scripts exploratorios y prototipos desechables, el enfoque es genuinamente útil y ha reducido la barrera para producir software funcional para usuarios con escasos conocimientos de programación. Para el software que debe mantenerse, auditarse y ser confiable en producción, la generación de aceptar-todo produce código difícil de razonar, frecuentemente frágil en casos extremos y expuesto a vulnerabilidades de seguridad que nadie leyó con suficiente atención para detectar. La reputación de la programación asistida por IA ha sufrido en consecuencia.
La respuesta profesional a este modo de falla es la disciplina conocida como ingeniería de prompt y de contexto. La ingeniería de prompt se refiere a la formulación de las instrucciones proporcionadas al modelo: su especificidad, su estructura, los límites explícitos que establece y los criterios por los cuales se juzgará el éxito. La ingeniería de contexto, la práctica más amplia, se refiere a la curación de todo lo que el modelo ve dentro de su ventana de contexto durante una tarea, incluyendo el prompt del sistema, el archivo de memoria del proyecto, los archivos fuente relevantes, la conversación anterior, las definiciones de herramientas y las salidas de herramientas ya invocadas. La complejidad no se elimina; se traslada de la interacción momento a momento a un entorno deliberadamente diseñado en el que el agente puede confiar.
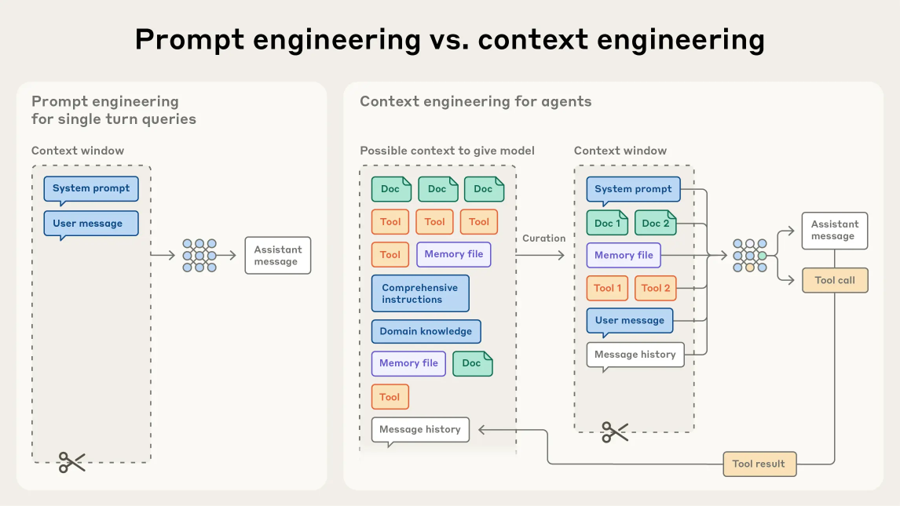
Prompt engineering vs. context engineering (anthropic.com/engineering/effective-context-engineering-for-ai-agents)
Las implicaciones prácticas son concretas. Una solicitud para refactorizar un módulo no es una sola oración escrita en una caja de chat; es un pequeño proyecto que comienza con el agente leyendo el archivo de memoria del proyecto, continúa con una revisión del código fuente relevante, produce un plan que nombra los cambios propuestos y las pruebas que los validarán, y solo entonces ejecuta el plan en etapas, con cada etapa verificada antes de que comience la siguiente. Las pruebas y la cobertura de código, lejos de ser preocupaciones secundarias, se convierten en la red de seguridad que permite que la iteración permanezca sin miedo. El código generado por IA sin cobertura rigurosa es una responsabilidad de mantenimiento esperando manifestarse; el código generado por IA acompañado de una suite de pruebas sólida puede modificarse, extenderse y depurarse con confianza.
Desde una perspectiva de planificación, este cambio reformula el papel del ingeniero. La contribución más valiosa ya no es el volumen de código escrito sino la calidad del contexto proporcionado, la precisión de los planes aprobados y el rigor de la verificación aplicada. El modelo proporciona capacidad de razonamiento a una escala que ningún ingeniero individual puede igualar; el ingeniero proporciona juicio, conocimiento de dominio y responsabilidad por el resultado.
Conclusiones
Ocho años separan «Attention Is All You Need» de los agentes de programación autónomos ahora en uso cotidiano. El camino recorre la arquitectura Transformer, la era de las leyes de escalamiento, los avances de alineamiento que hicieron confiable el seguimiento de instrucciones, los modelos de razonamiento que extendieron la capacidad hacia la planificación de múltiples pasos y el herramental agéntico que puso todo ello dentro del espacio de trabajo del ingeniero. Los modelos de razonamiento capaces de planificación de múltiples pasos, cuando se combinan con un harness bien diseñado que expone herramientas, estructura la memoria del proyecto y separa la planificación de la ejecución, hacen posible asumir tareas de ingeniería más grandes que lo que era práctico hace solo unos años. Las restricciones de estos modelos, en particular la ausencia de memoria persistente entre sesiones y la ventana de contexto finita, son reales pero manejables mediante una práctica de ingeniería disciplinada.
La promesa de estas herramientas es significativa, pero solo cuando se realiza a través de una ingeniería de prompt y de contexto suficientemente disciplinada para ser confiable. Para las organizaciones cuyos modelos analíticos y herramental sustentan decisiones que importan, la implicación es directa: los próximos años recompensarán a quienes inviertan en este oficio con la misma seriedad con la que han invertido en el oficio de la modelización en sí mismo.
