






Introducción
Razonamiento de IA en matemáticas
Durante la mayor parte de la era del aprendizaje profundo, la relación entre los modelos de lenguaje de gran escala y las matemáticas fue incómoda: los sistemas que sobresalían en la generación de lenguaje natural seguían siendo poco confiables en el razonamiento de múltiples pasos y en las matemáticas formales. Eso cambió rápidamente después de 2024, cuando los sistemas de frontera alcanzaron un rendimiento de nivel olímpico y comenzaron a integrarse directamente con entornos de verificación formal como Lean.
Más interesante que la progresión en los benchmarks en sí, sin embargo, es lo que esta capacidad significa para los matemáticos en ejercicio. Terence Tao se ha convertido en una de las voces más claras para articular el papel emergente de la IA en la investigación matemática. En un artículo de enero de 2025 en los Notices of the American Mathematical Society sobre prueba asistida por máquina, y más tarde a través de la publicación de una formalización flexible de su libro de texto Analysis I en Lean, Tao argumentó no que los modelos de lenguaje hubieran superado a los matemáticos, sino que se habían convertido en colaboradores útiles. Su valor radica en reducir la sobrecarga en torno a la investigación: buscar literatura, verificar argumentos estándar, formalizar definiciones, escribir pequeños experimentos computacionales y comprobar si un enfoque vale la pena seguir. En 2023, Tao ya había usado ChatGPT junto con Lean en trabajos relacionados con la formalización de aspectos de una prueba de la Conjetura Polinomial de Freiman–Ruzsa.
El cambio relevante, por lo tanto, no es meramente que los sistemas de IA puedan resolver problemas matemáticos más difíciles, sino que son cada vez más capaces de operar en razonamiento formal, manipulación simbólica, generación de código y verificación dentro de un flujo de trabajo unificado.
Razonamiento de IA en programación
La trayectoria en la ingeniería de software es estructuralmente similar a la de las matemáticas, aunque más visible porque sus salidas son código incorporado en lugar de pruebas escritas. El cambio es de autocompletar al estilo de sugerencia hacia sistemas agénticos que inspeccionan repositorios, planifican ediciones en múltiples archivos, ejecutan pruebas e iteran sobre fallos. Benchmarks como SWE-bench Verified ahora evalúan estos sistemas en problemas reales de GitHub extraídos de repositorios de producción, y para 2026 los agentes de frontera ya resolvían una fracción sustancial de las tareas de ingeniería de software a nivel de repositorio en bases de código previamente no vistas.
Más allá de los benchmarks, la señal industrial es cada vez más difícil de ignorar. Para 2026, los agentes de programación se habían integrado en los flujos de trabajo diarios de las principales organizaciones de ingeniería para tareas de refactorización, depuración, migración y generación de pruebas. Los ejecutivos de Anthropic afirmaron públicamente que Claude ya estaba escribiendo la mayor parte del código interno de la empresa, mientras que el informe DORA State of AI-Assisted Software Development 2025 de Google encontró que la adopción de IA se asociaba ampliamente con mayor productividad de ingeniería, con la productividad dependiendo tanto de la infraestructura de pruebas y la disciplina operacional como del modelo específico utilizado.
Leídas en conjunto, las trayectorias de la IA para las matemáticas y la IA para el código están convergiendo. Cuando se les suministra tanto un artículo de investigación como una base de código, los sistemas de frontera pueden participar en un ciclo acoplado de razonamiento e implementación: interpretar algoritmos, identificar condiciones de corrección, traducirlos a código de producción, generar pruebas de regresión e iterar a través de la ejecución y la verificación. El resto de este artículo informa un experimento deliberado en exactamente ese flujo de trabajo, con el humano estableciendo objetivos de alto nivel, aprobando estrategias de implementación e interviniendo principalmente cuando las pruebas exponían fallos algorítmicos o de convergencia.
La aplicación: expansión estocástica de la generación
LightBDMM.jl es un paquete Julia de PSR desarrollado en este entorno. Implementa el algoritmo de Descomposición de Benders Acelerada con Múltiples Maestros (a-BDMM) que fue introducido en el artículo: An Integrated Progressive Hedging and Benders Decomposition with Multiple Master Method to Solve the Brazilian Generation Expansion Problem (A. Soares, A. Street, T. Andrade y J. D. Garcia). La estructura del paquete, la implementación, las pruebas de regresión, la documentación y la configuración de integración continua fueron generadas por Claude Code, y luego corregidas iterativamente mediante ejecución, pruebas, depuración y revisión humana. Las extensiones posteriores — decisiones de primera etapa de enteros mixtos (MIP) con linearización de penalidad cuadrática, y ejecución distribuida a través de MPI — fueron añadidas por el mismo asistente.
El proyecto fue deliberadamente configurado como un experimento de baja interacción: ¿hasta dónde puede llevar un sistema agéntico de frontera una implementación de matemáticas aplicadas cuando el autor humano se limita a objetivos de alto nivel y revisión del estado final, en lugar de orientación paso a paso? La corrección durante el ciclo estuvo anclada no en la revisión humana de los pasos intermedios, sino en un conjunto de validación de ground-truth independiente, que se describe más adelante.
Ya contábamos con implementaciones de descomposición de Benders y Progressive Hedging en repositorios separados con paralelización MPI y representación de enteros mixtos. Estos repositorios fueron suministrados al agente de programación como implementaciones de referencia para patrones arquitectónicos, procedimientos de prueba y estructura de documentación.
La estructura matemática subyacente a la expansión estocástica de la generación es el programa estocástico de dos etapas: una decisión de inversión hoy (qué unidades construir, qué líneas reforzar, qué contratos firmar) se toma antes de que la incertidumbre del próximo año (demanda, hidrología, precios de combustible, producción renovable) sea observada; una decisión de recurso operacional se toma entonces una vez que cada escenario se ha materializado.
El ciclo de razonamiento matemático
El aspecto interesante de esta implementación no fue la matemática simbólica ni la demostración automática de teoremas. El desafío fue traducir un artículo de investigación en un paquete de optimización funcional: comprender la estructura algorítmica, planificar la implementación, identificar los desafíos de convergencia y corregirlos iterativamente mediante pruebas y validación. Este experimento solo fue significativo porque la corrección pudo verificarse de forma independiente: cada implementación fue continuamente validada frente a soluciones de equivalente determinístico y comportamiento de referencia, en lugar de juzgarse solo por si el código generado parecía plausible.
El algoritmo a-BDMM aumenta el Benders clásico en dos ejes. Los múltiples maestros reemplazan el maestro agregado único por un maestro por escenario, cada uno anclado en un problema de recurso diferente y compartiendo un pool de cortes común, lo que produce una aproximación de recurso más ajustada en menos iteraciones. La aceleración por Progressive Hedging añade una penalidad de consenso cuadrática que dirige las decisiones por escenario hacia un valor común.
Lo que hace al algoritmo una prueba útil del razonamiento matemático de IA es que varias de sus condiciones de corrección no son obvias a partir de la descripción principal y serían fáciles de omitir en una reimplementación ingenua:
- Un LP separado para el límite inferior después de que se activa el PH. Una vez que la penalidad de consenso está activa, el límite inferior del algoritmo debe calcularse a partir de un maestro que contenga solo el término Lagrangiano ws (xs – x) y no la penalidad cuadrática. La implementación mantiene un segundo pool de maestros de límite inferior exactamente para este propósito.
- Si el PH se inicializa en un punto degenerado, por ejemplo, con todos los componentes de $x$ iguales a cero, el algoritmo puede converger prematuramente a una solución de consenso que, sin embargo, es subóptima.
Trabajar con estos problemas requirió un proceso iterativo de planificación y depuración. Antes de escribir código, el asistente generó planes de implementación, identificó riesgos de convergencia y propuso estrategias de estabilización. Estas observaciones aún requerían verificación humana, pero identificarlas temprano redujo la probabilidad de propagar errores conceptuales a la propia implementación.
El ciclo de programación
El ciclo de programación fue la segunda etapa del proceso y siguió el mismo protocolo de baja interacción. Claude Code generó la estructura del paquete, la implementación, las pruebas de regresión, la documentación y la configuración de integración continua, mientras que el autor humano proporcionó solo especificaciones de alto nivel al inicio de cada ciclo y revisó las salidas finales. El punto importante no era que la primera implementación fuera correcta, sino que el agente pudiera mantener el repositorio, el algoritmo y la retroalimentación de las pruebas en contexto mientras iteraba hacia una implementación validada.
La implementación inicial ya reproducía la mayor parte de la estructura algorítmica correctamente, incluyendo el flujo de trabajo de la descomposición de Benders y el problema de prueba de referencia del newsvendor. El primer problema importante apareció en la lógica de agregación de cortes: la implementación inicialmente producía valores objetivos incorrectos porque las contribuciones de los escenarios no se combinaban adecuadamente. Tras corregir la agregación y la ponderación de los cortes, la variante BDMM convergió rápidamente y produjo la solución esperada.
El fallo más interesante emergió en la variante acelerada a-BDMM. Todas las variables de estado se inicializaron en cero, y los términos de penalidad del Progressive Hedging inmediatamente dirigieron el algoritmo hacia el consenso en torno a este punto inicial desinformado. Como resultado, el método quedó atrapado en una solución subóptima de «no hacer nada» y no logró mejorar. La corrección final fue introducir una fase de calentamiento en la que la descomposición exploró libremente durante varias iteraciones antes de activar las penalidades de consenso. Una vez implementada, esta estrategia de estabilización resolvió el problema de convergencia en los problemas de referencia y correspondió a la intuición de que los mecanismos de acuerdo no deben dominar antes de que se hayan generado cortes informativos.
La lógica del límite inferior, sin embargo, requirió un proceso de depuración mucho más interactivo. Una vez que las penalidades cuadráticas del PH se volvieron activas, el cálculo del límite inferior dejó de comportarse de forma consistente. Varios intentos de implementación fallaron de diferentes maneras: usar el límite superior como proxy produjo una convergencia artificial en la primera iteración; usar los objetivos brutos de los maestros causó límites inferiores oscilatorios después de la activación del PH; y substraer las penalidades cuadráticas directamente a veces generaba estados inválidos con LI > LS.
A diferencia del mecanismo de calentamiento, que emergió con relativamente poca intervención humana, la fase del límite inferior requirió interacción repetida entre el autor humano y el asistente. El proceso de depuración acabó siendo menos sobre ingeniería de software y más sobre interpretación computacional del propio algoritmo: determinar qué cantidades seguían siendo límites inferiores válidos después de la activación del PH, cómo debía medirse la convergencia y qué partes del objetivo aumentado eran artefactos de optimización en lugar de componentes del programa estocástico original. La implementación final acabó recuperando un procedimiento de límite inferior correcto descrito en el artículo.
En general, el proceso de depuración fue notable porque la mayoría de los fallos no eran problemas sintácticos o de ingeniería de software, sino desafíos algorítmicos relacionados con el comportamiento de convergencia y la interacción entre los mecanismos de descomposición y consenso.
Validación en un modelo de expansión de la generación
El solver fue evaluado en un problema de expansión estocástica de la generación — quince plantas candidatas, cuarenta y cinco clientes industriales y cincuenta escenarios estocásticos de activación. Cada método se ejecutó hasta una brecha relativa del 0,1% con la misma tolerancia.
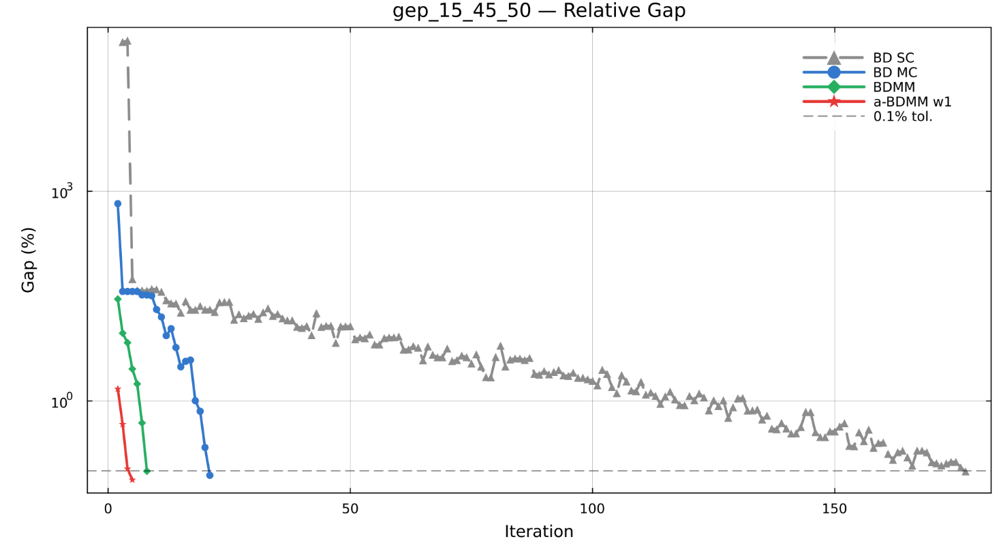
Figura 1 — Gap de otimalidade relativo em função do número de iterações para cada algoritmo no testbed de expansão da geração. O a-BDMM colapsa o gap em 5 iterações, contra 8 para o BDMM simples, 21 para o Benders de corte múltiplo e 177 para o Benders de corte único.
El resultado cualitativo de interés es la cantidad de iteraciones. El a-BDMM cierra la brecha de límite en 5 iteraciones, frente a 177 iteraciones para el Benders de corte único clásico en la misma instancia — una reducción de aproximadamente 35 veces. El BDMM simple (sin la aceleración del Progressive Hedging) se sitúa en el medio, con 8 iteraciones, aislando la contribución de la penalidad de consenso.
El conjunto de validación
En un protocolo de desarrollo de baja interacción, el conjunto de validación no es meramente una herramienta de garantía de calidad; es el mecanismo que hace viable el flujo de trabajo. Cada prueba de regresión en el conjunto se resuelve tanto con LightBDMM.jl como con el equivalente determinístico monolítico — la formulación extensiva exacta del programa estocástico utilizada como solución de referencia independiente. Los resultados deben coincidir en cada instancia de referencia, de modo que la implementación se verifique continuamente frente a una ground-truth externa y no solo frente a su propia lógica interna. Esto sirve como la contrapartida numérica del ciclo de razonamiento anterior: las condiciones identificadas durante la planificación y la depuración se revalidan computacionalmente frente a un benchmark que no comparte ninguna de las implementaciones de LightBDMM.jl. Cualquier desviación conceptual o de implementación introducida durante el ciclo de programación agéntica aparecería por lo tanto como una discrepancia con el equivalente determinístico antes de llegar a producción.
El conjunto completo de regresión se ejecuta en integración continua en cada cambio de código propuesto. En el momento de escribir este texto, el paquete mantiene aproximadamente un 98% de cobertura de código automatizada.
Perspectivas
El experimento no demuestra ingeniería matemática autónoma. Demuestra algo más restringido pero operacionalmente importante: cuando los algoritmos tienen estructura matemática sólida, comportamiento de referencia y procedimientos de validación independientes, los sistemas de programación agéntica pueden reducir sustancialmente el costo de ingeniería de traducir métodos de investigación en implementaciones de producción.
La optimización estocástica de dos etapas es uno de los marcos más antiguos y mejor comprendidos en investigación operativa, y el a-BDMM en sí mismo ha existido en la literatura desde 2021. El cambio relevante, por lo tanto, no es la novedad del algoritmo, sino la reducción en el costo y el tiempo necesarios para pasar del artículo al software probado. En este caso, la combinación de estructura matemática, validación de equivalente determinístico y desarrollo asistido por IA hizo posible construir una implementación de calidad de producción incluyendo variantes de descomposición, pruebas de regresión, infraestructura de benchmarking, integración continua y documentación, todo dentro de un único ciclo de desarrollo.
De forma más amplia, los dominios matemáticamente estructurados con soluciones de referencia independientes parecen especialmente compatibles con los flujos de trabajo de desarrollo agéntico. Cuando grandes partes de la traducción del artículo a producción pueden acelerarse y validarse continuamente, las organizaciones ganan la capacidad de experimentar, operacionalizar e implementar una fracción mucho mayor de la literatura de optimización de lo que era anteriormente práctico.
