






Introduction
Hydropower is the world’s largest source of low-carbon electricity, supplying close to one-seventh of global generation. Beyond its sheer scale, it is also one of the most flexible resources in modern power systems: large reservoirs can store water for months and release it on demand, smoothing seasonal variability and absorbing shocks elsewhere in the system. That same storage capacity, however, is what makes hydrothermal scheduling such a difficult planning problem. A decision to turbine or hold water today may not show its true cost or value until many months later, and that long memory must be reconciled with day-to-day operational realities such as transmission limits, thermal plant availability, and growing renewable variability.
For more than three decades, a central tool for this problem has been Stochastic Dual Dynamic Programming (SDDP), an algorithm deployed in operation planning studies in countries such as Brazil, Bolivia, Norway, Vietnam and the United States. In its classical form, SDDP relies on two structural assumptions: uncertainty must be represented in a way that preserves stagewise independence after a suitable transformation, and the underlying optimization problem must be convex. These assumptions are part of what makes the method tractable at scale, but they also shape the modeling choices available in practice, for example in how inflow processes are represented.
This article summarizes a recent study that explores an alternative path: combining optimization with Reinforcement Learning (RL) in a way that keeps the rigor of constraint enforcement while loosening the stagewise-independence assumption that SDDP imposes on the inflow model. The goal is not to replace SDDP, which remains a strong benchmark, but to understand what becomes possible when that structural restriction is relaxed, and at what cost.
Deep Reinforcement Learning in the Power Systems setting
Deep Reinforcement Learning (DRL) has gone through an unusually rapid maturation in the last decade. The field broke through with agents that learned to play Atari games from raw pixels, then went further with AlphaGo and AlphaZero, which mastered Go, chess and shogi entirely from self-play. More recently, the same family of techniques has become a routine ingredient in training large language models through reinforcement learning from human feedback. Each of these milestones pushed the algorithms forward: sample-efficient actor-critic methods such as Deep Deterministic Policy Gradient (DDPG), Twin Delayed DDPG (TD3) and Soft Actor-Critic (SAC), and model-based variants that plan over an internal model of the environment. The result is a toolbox that is far more practical, far more stable, and far less data-hungry than what was available even five years ago.
Underneath the algorithmic variations, all RL methods share a common structure: a loop between an agent and an environment. At each time step, the agent observes the state of the environment and chooses an action; the environment transitions to a new state and returns a reward that scores the choice. Repeating this loop over the full horizon defines an episode. The agent’s goal is to learn a policy (a rule that maps observed states to actions) that maximizes the cumulative reward over an episode.
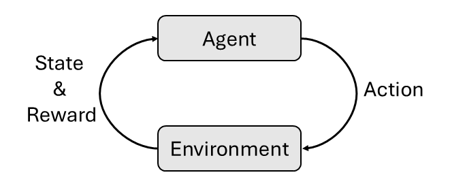
Figure 1 – The reinforcement learning framework
From a power-systems standpoint, what makes DRL interesting is its underlying kinship with the algorithms operators already use. Value-based DRL and SDDP are surprisingly close cousins: both alternate between a forward simulation step and a backward update that improves an estimate of the long-term cost-to-go function. SDDP represents that function with piecewise-linear convex cuts, which is what gives it its remarkable efficiency on convex problems. DRL replaces those cuts with neural networks, which are universal function approximators. Interestingly, when the network uses ReLU activations, as most modern architectures do, the resulting cost-to-go approximation is also piecewise linear, but no longer required to be convex. In other words, DRL can be read as a generalization of the same idea behind SDDP.
That generalization is starting to translate into concrete power-system applications. DRL has been used for real-time energy dispatch in IoT-driven microgrids (Lei et al., 2021), and recent surveys document a fast-growing range of additional use cases, including voltage and reactive power management on distribution feeders, bidding strategies in electricity markets, and the operation of battery storage in systems with high renewable penetration (Sivamayil et al., 2023).
The hydrothermal dispatch problem is another use case, marked by a multi-year horizon driven by reservoir time coupling, and by hard physical constraints on the network and on water balances. DRL’s cost-to-go approximation can represent the nonlinear, time-coupled value of stored water across that horizon, but the constraints are a weak point for pure RL approaches. Pairing DRL with an optimization layer that enforces those constraints at each stage is what makes this hybrid approach viable in practice.
The proposed approach: target tracking with a learned policy
The method has two components that work in tandem. At each monthly stage, an optimization problem decides which thermal and hydro plants to dispatch, satisfying load balance, water balance, generation limits, and the full set of network constraints. What changes is how the long-term value of stored water is communicated to that single-stage problem. Instead of the piecewise-linear cost-to-go function used by SDDP, an RL agent (implemented here as a DDPG actor-critic) outputs a target reservoir volume for each hydro plant, together with a penalty weight that controls how strongly the operation should be pushed toward that target.
The single-stage problem then minimizes immediate operating cost plus a penalty on the deviation between the final reservoir volumes and the targets supplied by the agent. If the agent recommends keeping reservoirs full, water is stored aggressively; if the agent prefers to draw down, the optimization releases water to the extent the constraints allow. The simulated operating cost is fed back as a reward signal, and the actor and critic networks are gradually trained to recommend targets that minimize total cost across the full planning horizon.
Two design choices are worth highlighting. First, the optimization layer is what guarantees feasibility: the RL agent never has to learn what a network constraint is, because the optimizer enforces it for every dispatch decision. Second, splitting the problem in this way (single-stage optimization for the immediate decision, RL for the long-term coupling) removes the structural restrictions that multistage solvers normally impose on the modeling. In particular, the inflow process can be any model that drives the simulation: historical data, a flexible time-series model, or any other process we believe better represents reality.
Figure 2 maps these pieces onto a single stage. The agent’s input is the current state st (reservoir levels and recent inflow lags) together with the stage’s realized uncertainties ωt (inflows and demand). Its action has two parts: a vector of target reservoir volumes ŝt+1 and a penalty weight βt that controls how strongly the optimizer should track those targets. Solving the state-tracking problem with these inputs yields the realized next state st+1 and the immediate operating cost ct, which is fed back as the reward signal used to train the agent.
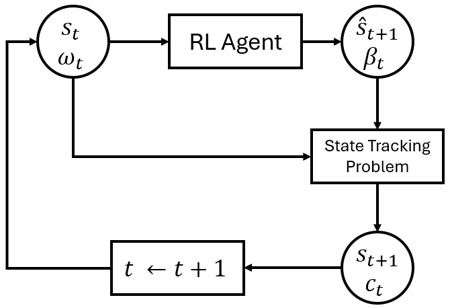
Figure 2 – Information flow between the RL agent and the single-stage state-tracking optimization problem.
Case study: inflow model
The proposed approach is benchmarked against SDDP in a setting where the structural assumptions of SDDP force a modeling simplification that the hybrid method can avoid: the stagewise-independent inflow model required by SDDP. The test system is the Bolivian power system (28 buses, 11 hydro plants, 23 thermal plants and 31 transmission branches), simulated over a 5-year horizon split into 60 monthly stages. Policies are compared on the same 10,000 out-of-sample inflow scenarios drawn from a SARIMA model fitted to the inflow history, and each RL configuration is trained five times with different random seeds to account for variability from neural network initialization.
SDDP was trained on scenarios from a PAR(p) model, as required by its stagewise-independence assumption. Three RL variants were trained on different inflow inputs: the artificial historical record itself, a SARIMA-based generator matching the out-of-sample data-generating process, and the same PAR(p) model used by SDDP.
The results show a clear ordering among the RL variants. Training on scenarios drawn from the true data-generating process, even a limited number of them, produced lower operating costs than training on PAR(p) scenarios, with a roughly 5% reduction. Drawing an unlimited number of SARIMA scenarios pushed costs down further, confirming that flexible inflow models combined with abundant training data lead to better policies. SDDP nonetheless finished ahead of all RL variants, with the best RL configuration landing within about 5% of the SDDP cost.
Two practical observations emerged. First, the inflow modeling assumption commonly used in operational planning is not innocuous: replacing PAR(p) with a richer stochastic process changed total operating costs by several percentage points, with every other assumption held fixed. Second, seed variability had a meaningful impact: different initializations led to different end-of-horizon reservoir levels, reinforcing the importance of evaluating multiple seeds in any practical deployment.
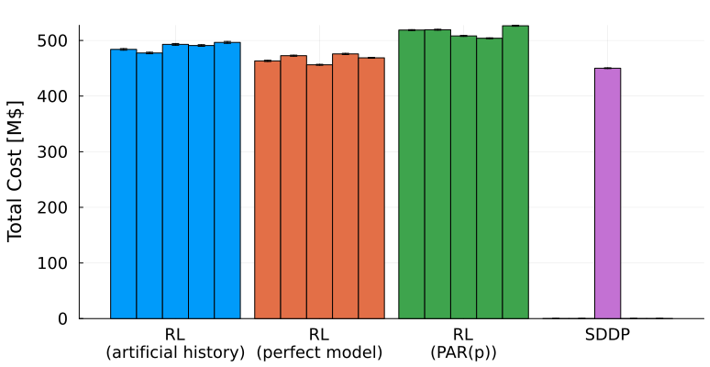
Figure 3 – Total operating cost across random seeds.
Discussion and outlook
The experiments support a measured conclusion. Combining optimization and Reinforcement Learning is a practical way to build hydrothermal dispatch policies without imposing the stagewise-independence assumption that SDDP requires on its inflow model. The single-stage optimizer keeps every physical constraint feasible, while the learned policy provides the temporal coupling that SDDP would otherwise enforce through its piecewise-linear cost-to-go function. Within that framework, training the policy on scenarios closer to the true data-generating process lowered costs in a consistent way across seeds, suggesting that the PAR(p) restriction routinely embedded in operational planning carries real economic weight. The honest counterpoint is that SDDP remained the more cost-effective approach under the conditions tested. The hybrid method narrowed the gap when the inflow model was relaxed, but it did not close it.
Several research directions look promising to further explore the potential advantages of DRL. Parallelizing the inner optimization across scenarios would improve training efficiency, particularly when the per-stage solve is expensive, for example when richer network or operational constraints are introduced. More recent RL algorithms such as Twin Delayed DDPG and Soft Actor-Critic address some of the stability issues of DDPG and could improve sample efficiency. And because we already have an explicit model inside the optimization layer, model-based RL (the family of algorithms behind systems such as AlphaZero) is a natural fit: the agent could evaluate several candidate target volumes by solving the single-stage problem for each, and use that information to plan ahead more effectively.
DRL itself is a developing toolset rather than a finished product. The field has advanced substantially in the past few years, with more stable training algorithms, better sample efficiency, and active research on scaling to the kinds of large state and action spaces characteristic of power systems. For long-horizon planning problems such as hydrothermal dispatch, we believe the most likely path forward is hybrid: optimization handles what it does best, namely enforcing physical constraints and producing tractable per-stage decisions, while DRL handles the temporal coupling and the parts of the problem that resist convex modeling.
References
Pereira, M.V.F. and Pinto, L.M.V.G. (1991). Multi-stage stochastic optimization applied to energy planning. Mathematical Programming, 52(1), 359–375.
Rosemberg, A.W., Street, A., Garcia, J.D., Valladão, D.M., Silva, T. and Dowson, O. (2022). Assessing the cost of network simplifications in long-term hydrothermal dispatch planning models. IEEE Transactions on Sustainable Energy, 13(1), 196–206.
Lillicrap, T.P. et al. (2015). Continuous control with deep reinforcement learning. arXiv:1509.02971.
Lei, L., Tan, Y., Dahlenburg, G., Xiang, W. and Zheng, K. (2021). Dynamic energy dispatch based on deep reinforcement learning in IoT-driven smart isolated microgrids. IEEE Internet of Things Journal, 8(10), 7938–7953.
Sivamayil, K., Rajasekar, E., Aljafari, B., Nikolovski, S., Vairavasundaram, S. and Vairavasundaram, I. (2023). A systematic study on reinforcement learning based applications. Energies, 16(3).
