






A new generation of large language models with explicit reasoning capabilities has changed what is possible in software development. Earlier code-completion tools relied on statistical pattern matching and were useful primarily for short, local suggestions. The latest reasoning models can decompose engineering problems into intermediate steps, plan a sequence of actions, inspect their own work, and iterate toward a solution. When this reasoning capability is embedded in an appropriate execution environment, an entirely different practice becomes available, one in which the human engineer is no longer the sole producer of code but the architect of a process that includes an autonomous coding agent.
From the Transformer to reasoning models
The path that leads to today’s coding agents has earlier roots in decades of work on neural language modeling, recurrent architectures, and prior attention mechanisms, but its decisive milestone came in 2017 with the publication of “Attention Is All You Need” by Vaswani and colleagues, most of them at Google Brain and Google Research. The paper introduced the Transformer, a neural-network architecture that replaced the recurrent and convolutional layers then dominant in language modeling with a mechanism based entirely on self-attention. The Transformer turned out to be unusually well-suited to scaling, in both parameter count and training data, and it has remained the substrate of essentially every large language model released since.
The first wave of practical implications appeared in 2018 with GPT-1, OpenAI’s generative pre-training approach, and BERT, Google’s bidirectional encoder. Both established the now-dominant paradigm of pre-training on large corpora of unlabeled text and then fine-tuning on narrower tasks. The differences between the two designs (decoder-only versus encoder-only, autoregressive versus masked) shaped the divergent application paths that followed.
The 2019–2020 period made scaling itself the central question. GPT-2 demonstrated that a moderately larger model trained on more text produced qualitatively better text. GPT-3, with 175 billion parameters, showed in 2020 that further scaling unlocked in-context learning, the ability to perform new tasks given only a handful of examples in the prompt. The scaling laws published the same year by Kaplan and colleagues offered a quantitative framework for how loss decreased with parameters, data, and compute, and they shaped much of the field’s subsequent investment.
The 2022 turning point was alignment rather than capability. InstructGPT and the closely related techniques behind ChatGPT (released in November 2022) used reinforcement learning from human feedback (RLHF) to make models follow instructions reliably and refuse plainly inappropriate requests. The technique fine-tunes a pre-trained model through a reward model that learns from human preferences over candidate completions, shaping the model’s outputs toward responses humans’ rate as helpful, honest, and safe. The technical advance was modest in absolute terms; the user-experience advance was decisive. Within months, the underlying technology had reached a mass audience.
The 2023–2024 period saw the proliferation of providers and the rise of multimodality. GPT-4, Anthropic’s Claude, Google’s Gemini, and Meta’s Llama family (the latter as open weights) all reached general availability, with most adding image, audio, or video understanding. Code-completion tools that had existed at smaller scales since 2021, most notably GitHub Copilot, gained GPT-4-class chat features (Copilot Chat moved to GPT-4 in late 2023), and the quality of assistance improved correspondingly.
The next axis appeared in late 2024 with OpenAI’s o1 family of reasoning models, followed in early 2025 by DeepSeek’s R1, the first widely used open-weights reasoning model, and later that year by OpenAI’s o3 family. The technical idea was that a model could be given more compute at the time of answering rather than only at training time and could spend that compute on chain-of-thought reasoning, self-checking, and iterative refinement. For tasks involving multi-step planning, mathematics, and code, the gains were substantial. By 2025 the leading model families across providers all included reasoning variants. Anthropic folded extended thinking into the Claude family, OpenAI shipped the GPT-5 generation as a reasoning-first family, and reasoning had become a baseline expectation rather than a frontier feature.
The combination of capable reasoning models and the engineering needed to give them tools, file-system access, and execution environments produced the wave of agentic coding tools that define the current period. Through 2025, a new class of command-line agents reached general availability, including GitHub Copilot Agent, Gemini CLI, and Anthropic’s Claude Code, while editor-integrated tools, such as Cursor, extended the same pattern into the IDE. Within months, the unit of interaction had moved from the line of code to the engineering task.
| Era | Core Breakthrough | Primary Value in Software Engineering |
| 2017–21 | Transformers and Scaling | Statistical pattern matching and line-by-line completion |
| 2022–23 | Alignment (RLHF) and Chat | Conversational assistance, explaining code |
| 2024–25 | Reasoning at Inference | Multistep planning, chain-of-thought, self-correction |
| 2025– | Agentic Scaffolding (Harness) | Autonomous file editing, CLI execution, Model Context Protocol (MCP) integration |
The narrative arc is consistent across these milestones: architecture (the Transformer) made scaling possible; scaling produced capability; alignment made the capability accessible; reasoning extended the capability into multistep tasks; and tooling turned the resulting models into autonomous engineering agents. Each turning point opened the door to the next.
Foundation models and their constraints
Underneath every coding agent lies a foundation model. The major providers (Anthropic with Claude, OpenAI with GPT, Google with Gemini, plus a growing set of open-weight families such as Kimi K2 and Qwen 3) all follow a similar deployment pattern: the model is trained once and then served with frozen parameters. This pattern carries an important consequence: the model itself does not learn from one session to the next. It cannot form new permanent memories, and every new conversation begins with a blank slate. What the model “remembers” within a session is limited to the contents of its context window, the bounded sequence of tokens that includes the system prompt, the user’s instructions, prior exchanges, tool outputs, and the model’s own intermediate reasoning.
Each provider typically offers its models in tiers that balance capability, latency, and cost. While specific vendor branding shifts rapidly, the underlying pattern remains an industry standard: a flagship model for the hardest reasoning tasks (e.g., Anthropic’s Opus, OpenAI’s GPT-5, Google’s Gemini Pro), a balanced everyday model (Sonnet, GPT-5 mini, Gemini Flash), and a fast lightweight model (Haiku, GPT-5 nano, Gemini Nano). The choice of tier is a context-engineering decision, since heavier reasoning is rarely needed at every step of an engineering task and matching the tier to the difficulty of the subtask is a meaningful lever on quality, latency, and cost.
Modern context windows are large by historical standards. The most recent Gemini and GPT releases reach roughly one million tokens, the latest Claude generation reaches comparable lengths in its extended-context configurations, and open-weight models such as Kimi and Qwen sit in the low hundreds of thousands. They remain finite, however, and two related phenomena make their management non-trivial. The first is the simple truncation that occurs when the window fills: once the limit is reached, the oldest content is discarded, and the model loses access to it. The second, more subtle, is context rot: as the window approaches its capacity, accuracy degrades and the model begins to lose track of details even within content, still nominally present. Empirical benchmarks of long-context retrieval consistently show that more context is not always better. Recently, the introduction of prompt caching has mitigated some of these friction points by allowing models to recall massive codebases and system prompts cheaply and rapidly across turns, though it does not solve the fundamental limits of working memory.
These constraints matter operationally. The reasoning model has the capability to plan, write, and verify code, but it has neither persistent memory across sessions nor unlimited working memory within a session. The quality of any extended interaction therefore depends critically on what is placed inside the context window and what is kept out.
The agent’s harness
A coding agent is more than the foundation model that powers it. It is a harness that gives model-controlled access to a set of tools, a structured way of recording project knowledge, and a discipline for managing the boundary between planning and execution. Several agents now compete in this category, including GitHub Copilot Agent, Gemini CLI, Claude Code, Cursor, and Cline, and the architecture they share is broadly similar even where the surface vocabulary differs.
The agent operates inside a project directory and is equipped with a small set of fundamental tools: a file editor, a shell for running tests and builds, a web search and fetch capability, and a programmatic tool-calling interface. These primitives allow the agent to read source files, modify them in place, run the test suite, and consult external documentation, all without the engineer leaving the terminal. Two further mechanisms extend this baseline. The Model Context Protocol (MCP) is an open standard, released by Anthropic in late 2024, that allows agents to connect to external systems through a uniform interface, in much the same way that USB-C unified the proliferation of cables before it. Although Anthropic-authored, MCP is now adopted across a range of hosts that include Cursor, Cline, and several editor-integrated agents, which makes it a genuine portability layer rather than a vendor-specific protocol. A representative example is Context7, an MCP server that pulls updated, version-specific documentation for libraries and packages, allowing the agent to write against the API in current use rather than the API it happened to see during training. Skills are modular text-based capabilities, packaged as instructions and supporting resources, that the agent activates automatically when their description matches the task at hand.
A further element of recent harnesses is the introduction of structured user-interrogation tools, mature implementations of which (such as Claude Code’s AskUserQuestion) let the agent pause and put a multi-choice question to the engineer rather than guess at an ambiguous requirement. The mechanism is small but consequential, because the most frequent source of wasted work in agentic coding is the model proceeding confidently down the wrong interpretation of an instruction.
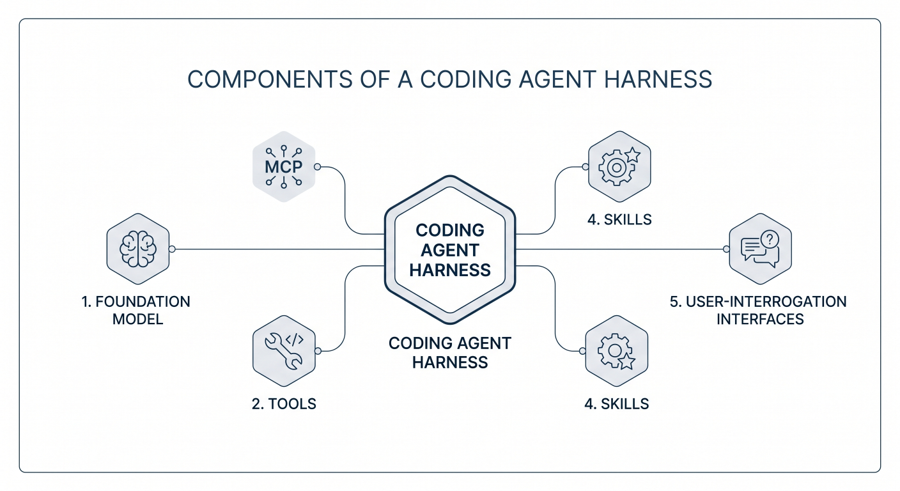
Coding-agent harness — foundation model, tools, MCP servers, skills, and user-interrogation interfaces.
Two harness features deserve particular attention because they directly address the memory and discipline problems described in the previous section. The first is the project memory file, a markdown document placed at the root of the project that the agent reads at the start of every session. The convention has converged across tools under different names: CLAUDE.md for Claude Code, GEMINI.md for Gemini CLI, AGENTS.md as a more recent cross-tool convention adopted by Cursor, GitHub Copilot, OpenAI Codex, and others. The file records the project overview, the conventions to follow, the commands that build and test the code, and any context that would otherwise have to be rediscovered each time. It is, in effect, the persistent memory that the model itself lacks. A well-maintained project memory file transforms what would be a stream of identical re-explorations into a series of focused interactions that begin with the relevant context already loaded.
The second is the discipline of separating planning from execution, implemented under various names across the tooling. In this mode the agent is prevented from editing files or running commands with side effects; it can only read, analyze, and propose. The output is a written plan that the engineer reviews and approves before any code changes occur. This separation prevents the agent from committing to an architectural direction that the human disagrees with, eliminates wasted work on premature implementations, and prevents the model from falling into an “agentic doom loop”, a common failure mode where a reasoning model repeatedly writes failing tests, attempts to fix them, and fails again without human intervention. The principle is straightforward: an autonomous agent should not be turned loose on a challenging task without a reviewed and approved plan.
Beyond vibe coding: prompt and context engineering
The accessibility of these tools has produced a contrasting development style sometimes referred to as vibe coding, a term coined by Andrej Karpathy in early 2025 to describe, in his phrase, a workflow in which the user “fully gives in to the vibes,” accepts the model’s diffs without reading them, pastes errors back without comment, and lets the code grow beyond their own comprehension. For exploration scripts and disposable prototypes, the approach is genuinely useful, and it has lowered the barrier to producing working software for users with limited programming background. For software that must be maintained, audited, and trusted in production, accept-all generation produces code that is difficult to reason about, often fragile under edge cases, and exposed to security weaknesses that no one ever read closely enough to catch. The reputation of AI-assisted coding has suffered accordingly.
The professional response to this failure mode is the discipline known as prompt and context engineering. Prompt engineering concerns the formulation of the instructions given to the model: their specificity, their structure, the explicit boundaries they establish, and the criteria by which success will be judged. Context engineering, the broader practice, concerns the curation of everything the model sees inside its context window during a task, including the system prompt, the project memory file, the relevant source files, the prior conversation, the tool definitions, and the outputs of tools already invoked. The complexity is not eliminated; it is moved out of the moment-to-moment interaction and into a deliberately engineered environment that the agent can rely on.
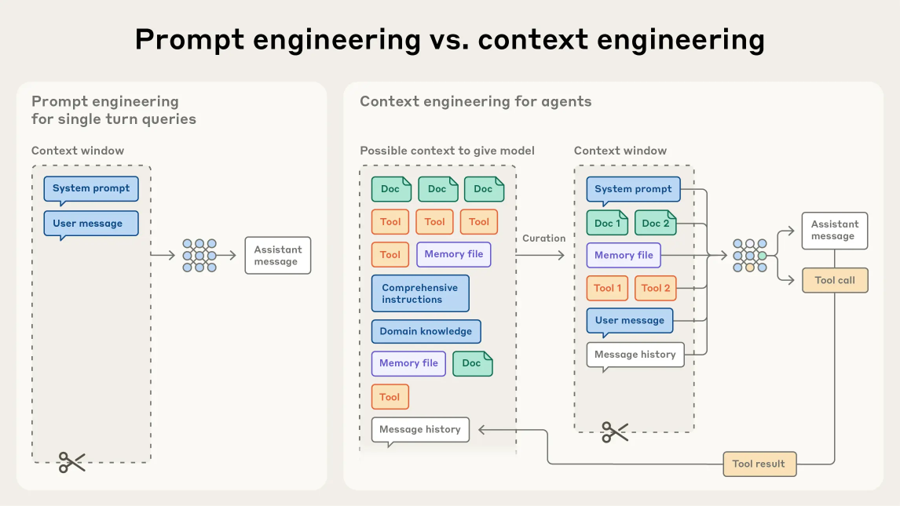
Prompt engineering vs. context engineering (anthropic.com/engineering/effective-context-engineering-for-ai-agents)
The practical implications are concrete. A request to refactor a module is not a single sentence typed into a chat box; it is a small project that begins with the agent reading the project memory file, continues with a review of the relevant source, produces a plan that names the proposed changes and the tests that will validate them, and only then executes the plan in stages with each stage verified before the next begins. Tests and code coverage, far from being secondary concerns, become the safety net that allows iteration to remain fearless. AI-generated code without rigorous coverage is a maintenance liability waiting to surface; AI-generated code accompanied by a strong test suite can be modified, extended, and debugged with confidence.
From a planning perspective, this shift reframes the engineer’s role. The most valuable contribution is no longer the volume of code written but the quality of the context provided, the precision of the plans approved, and the rigor of the verification applied. The model supplies reasoning capacity at a scale that no individual engineer can match, the engineer supplies judgment, domain knowledge, and accountability for the result.
Conclusions
Eight years separate “Attention Is All You Need” from the autonomous coding agents now in everyday use. The path runs through the Transformer architecture, the scaling-laws era, the alignment breakthroughs that made instruction-following reliable, the reasoning models that extended capability into multi-step planning, and the agentic tooling that put all of it inside the engineer’s workspace. Reasoning models capable of multi-step planning, when paired with a well-designed harness that exposes tools, structures project memory, and separates planning from execution, make it possible to take on larger engineering tasks than was practical only a few years ago. The constraints of these models, in particular the absence of persistent memory across sessions and the finite context window, are real but manageable through disciplined engineering practice.
The promise of these tools is significant, but only when realized through prompt and context engineering is disciplined enough to be trustworthy. For organizations whose analytical models and tooling underpin decisions that matter, the implication is direct: the coming years will reward those that invest in this craft as seriously as they have invested in the craft of modeling itself.
